Back to Basics: Table Space Scans for z/OS Db2
A tablespace Scan is chosen by the optimizer for the retrieval of data from a query for many different reasons, often times when no other access paths are available or when it is perceived to be less expensive than the alternatives. Tablespace scan is the equivalent of sequential access. Db2 may choose to use a tablespace scan even if there are indexes available, and the reasons for the optimizer not choosing an index is the key to this article. The scan can be chosen if you are retrieving 1 row from a table or millions of rows in a table. For most queries written, you do not want the optimizer to sequentially read through every row on every page of data in order to bring back an expected result set.
Most of the time when you code queries against a Db2 table(s), you want the optimizer to choose an index so as to retrieve the data the query is asking for faster. When someone notices an index is NOT being selected, and retrieving the data via a tablespace scan, this should be an automatic red flag to evaluate the query, tables, indexes, clustering, etc. and figure out why.
- How many rows are in the table
- How many rows are expected back from the query
- What are the indexes on the table
- How are the data rows physically clustered in the table
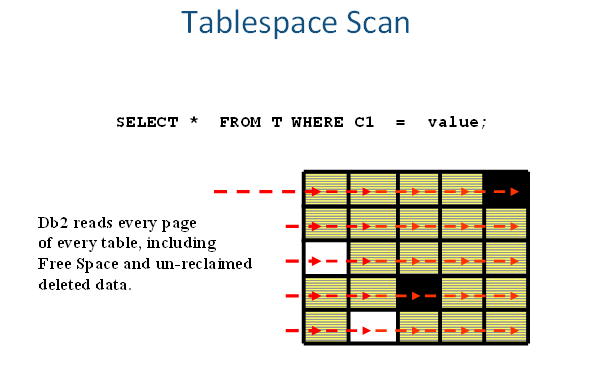
In this example, the predicate is specifying to only bring back the rows for a specific C1 value. If there is no index on the column C1 that was created on table T, then the optimizer has no choice but to scan through all the data evaluating every row on every page. If there are multiple tables in a tablespace, it will scan through all tables, regardless of which table a page belongs to.
How does someone know if a scan is occurring? Typically the response time in gathering the result set is slower than expected. But to be sure, executing a Db2 explain on the query will tell you. There are different tools for running an explain, and most of them are pretty obvious in showing that a scan is taking place.
When executing an explain on the mainframe version of Db2, the value ‘R’ will show up in the ACCESS_TYPE column of the PLAN_TABLE explain table. My understanding is that ‘R’ was chosen initially for Relation which is another term for Table.

If using the IBM Data Studio tool, the visual explain has an obvious node showing a scan. The number 2808 in this example represent the estimated cardinality to be returned. That means that the optimizer thinks that the query will be returning that many rows. Is the optimizer always correct in its estimation of rows to be returned for query? No, not always.
Other tools may show something like:

One reason a tablespace scan is chosen is because the optimizer in its calculations from a query’s logic has estimated a large number of rows is to be returned. Because of this, it chooses to skip all possible indexes, defaulting to the scan. To help in any query analysis, a key point is to know the typical result set returned.
Assuming that table T has no index on the column C1, and the following query is issued:
SELECT * FROM T WHERE C1 = value;
Db2 must read the rows on every page of data for table T in order to determine whether any row has its value of C1 matching the given value. I/O is done at the page level, bringing the pages containing the rows into its assigned buffer pool memory area. Each page requires a read operation. But, with tablespace scans comes along something called sequential prefetch noted as ‘S’ in the prefetch column of the PLAN_TABLE explain table.
Sequential Prefetch is a mechanism that enables Db2 to read a sequential set of pages in a single asynchronous I/O. Sequential Prefetch can provide substantial savings in both processor cycles and I/O costs. The maximum number of pages read into the buffer pool on the mainframe version of Db2 for each I/O operation is determined by the size of the buffer pool assigned to the table. This can be up to 64 pages per asynchronous I/O . Retrieving multiple pages per I/O makes the scan process faster, but still not the response you would typically expect unless retuning a large percentage of rows.
When a query is going to return a high percentage of rows in its result set, the optimizer often chooses a scan, thinking it will be faster than using an index. This is specific to sequential prefetch.
Many large tables have a partitioning design, where rows are spread out across many partition files based on a partitioning data scheme. In the following example, the data is partitioned by employee number.
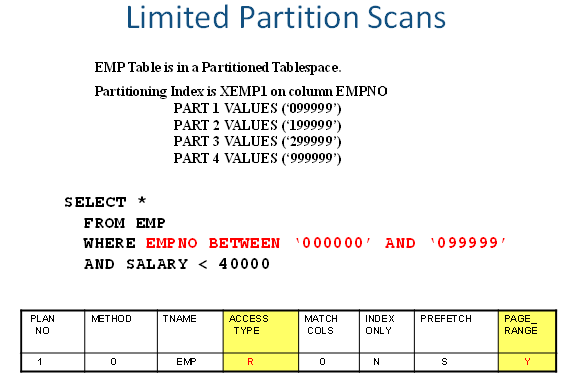
Note column PAGE_RANGE from the Db2 explain PLAN_TABLE. In this example it is showing a tablespace scan, but specific only to the partition(s) containing up to employee number ‘099999’. The optimizer knows the partitioning scheme, and sets a ‘Y’ in this column. This states that a scan will occur but only for a range of partitions, and not all. In this example, it would be for partition 1. If the value is blank, then the scan will go across all partitions.
Data Studio lays out tablespace scans in more detail via the visual explain graph:
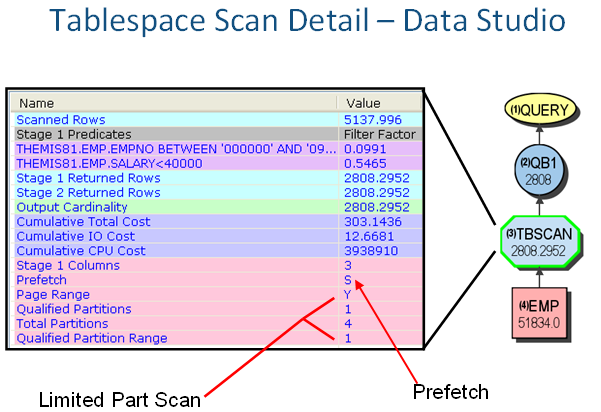
There are many different reasons why the optimizer will choose a tablespace scan. And for anyone doing analysis on a query, when a scan is occurring, you should first figure out why the optimizer has chosen that access path. Following is a list of reasons where the optimizer might choose to scan.
- The predicate(s) may be poorly coded in a non-indexable way. The way predicates are coded in SQL can determine whether the optimizer can make use of an index. For example most functions and mathematics on columns will eliminate an index if one exists on the predicate column:
WHERE RTRIM(LASTNAME) = ? è Non indexable predicate
WHERE HIREDATE – 7 DAYS > ? è Non indexable predicate
- If there exist an index on either of these columns, the optimizer will ignore the indexes if they exist. Db2 V11 on the mainframe now handles some SQL functions as indexable. Google ‘Top 25+ Tuning tips for Developers’ for more detail information on this topic.
- The predicates in the query do not match any available indexes on the table. In other words, if there is no viable index available, the only way for Db2 to access the data and qualify the rows is by reading every data row. Know your indexes!
- The table could be small, and DB2 decides a tablespace scan may be faster than index processing. NOTE: you should still have indexes on small tables.
- The catalog statistics say the table is small, or maybe there are no statistics on the table. A Db2 utility called Runstats gathers and updates data statistics about characteristics of data in a table space, index, and partition. This helps the optimizer in its analysis of determining both an access path and the number of rows to be returned. Make sure the statistics are up to date by querying the SYSIBM.SYSTABLES and SYSIBM.SYSCOLUMNS specific to tables involved. There is a column STATSTIME that states the last time a Runstats utility was run. Having up to date statistics helps the optimizer in figuring out how many rows can be expected back from the query. If the statistics are out of date, then the number of rows calculated are most likely not as accurate.
- The predicates are such that DB2 thinks the query is going to retrieve a large enough amount of data that would require a tablespace scan.
- The predicates are such that DB2’s index choice is a non-clustered index, and the number of pages to retrieve is high enough based on total number of pages in the table to require a tablespace scan. Data rows are stored on pages (typically 4K pages). One of the indexes created on a table determines the order of the data on the pages. For example: in the sample table EMP, the data is in employee number order (lowest to highest) specific to the index on that column having the parameter CLUSTER=YES.
What if the following query is being executed?
SELECT ….
FROM EMP
WHERE WORKDEPT in (‘A00’, ‘C11’, ‘D21’)
;
Where do these rows exist in the table of data? They exist across many different pages of data because the data is in employee number order. If there are 1000 employees in department ‘C11’, they could be scattered across 1000 pages of data. There does exist an index on the column WORKDEPT, but the optimizer may determine to not use that index if it thinks a large percentage of pages are to be retrieved. For example if the table only has 1500-2000 pages and the optimizer thinks upwards of 1000 pages may be retrieved, then it might choose a tablespace scan.
See the following for more detail on some of these topics:
Indexes
Db2 Index Overview - International Db2 Users Group (idug.org)
When Indexes Are Only Partially Effective - International Db2 Users Group (idug.org)
Db2 explain
Back to Basics: Db2 z/OS Access Paths and Db2 Explain - International Db2 Users Group (idug.org)