Db2 Index Overview
Indexes perform a critical role in any relational database and Db2 is no exception. Applications expect to receive near instant response when querying multi-billion row tables Indexing tables in a manner appropriate to the workload is a big part of a Database Administrator’s job. When no index exists to service a query then every row will be examined to determine which records qualify (i.e. tablespace scan). Let’s take a look at the way indexes work in a Db2 environment.
Readers can probably think of many practical (non database) examples of indexes. My favorite is a trip to your local library. We can think of the non-fiction section as an unordered collection of things (yes I know the Dewey Decimal Classification is not completely without order but work with me). When looking for a particular book (or group of books), one now uses the computer in the lobby to search for the desired book and then go to its relative location on the library shelf. In the old days the analogy is even better as the index existed in big cabinets with drawers and cards. There were three ways of looking things up (three indexes if you follow): subject, author and title. As long as you knew one of those things your book was easy to find even among tens of thousands of its peers. If you wanted to search by something else like publisher or author’s first name you would need to examine every book on every shelf.
Indexes in a RDBMS work in a very similar way. In a Db2 database, indexes are always stored separately from the data in the tables that they reference. Each row in the database has an address called a Record Identifier (RID) that may be used to directly locate the row with a single page request. An index is a sorted list of key values paired with the RIDs associated with those values.
Indexes are stored in a self-balancing tree (b-tree) structure with at least 2 levels. The number of levels needed will depend on the size of the index. The leaf page level consists of a sorted list of keys with the associated RIDs. The non-leaf levels provide a quick path to the leaf pages when columns are matched in the index by tracking the highest key value on each page below.
The example below demonstrates how an index may be used when columns are matched to locate only a few rows from a large table while only examining a few pages of the index. Once the appropriate entries are located at the leaf page level the tablespace pages containing the desired rows may be accessed directly. Notice that this index contains 3 columns but only the first 2 are used in the query. The index is still very useful in locating the desired result set.
The example below demonstrates how an index may be used when columns are matched to locate only a few rows from a large table while only examining a few pages of the index. Once the appropriate entries are located at the leaf page level the tablespace pages containing the desired rows may be accessed directly. Notice that this index contains 3 columns but only the first 2 are used in the query. The index is still very useful in locating the desired result set.
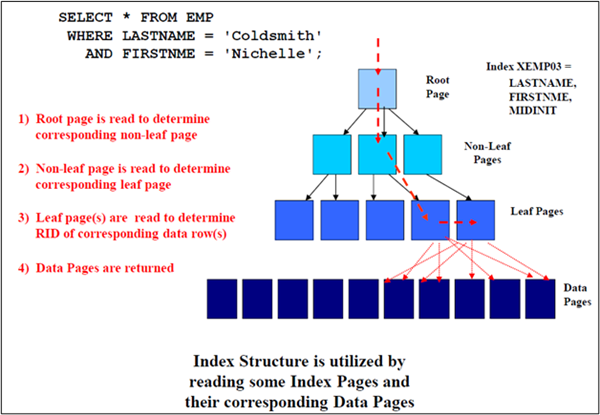
Think about some other ways this index could be used. Some are not ideal but may be the best available option for our data.
Example #1:
SELECT * FROM EMP
WHERE LASTNAME = ‘Coldsmith’
AND FIRSTNME LIKE ‘N%’Example #2:
SELECT * FROM EMP
WHERE LASTNAME = ‘Coldsmith’
AND FIRSTNME LIKE ‘N%’
AND MIDINT = ‘Q’Example #3:
SELECT * FROM EMP
WHERE FIRSTNME = ‘Nichelle’In the first example the index may be used and both columns will be matched. In other words, the index will direct Db2 to the first entry that matches the desired criteria and then Db2 will work through subsequent index pages to find the rest of the rows. No leaf pages will need to be examined that do not contain qualifying rows.
The second example makes use of all 3 columns in the index. However since the second column is a range predicate the third column will not be matched directly to rows. Range predicates contain comparison operators such as LIKE, BETWEEN, >, or <. These operators identify ranges of values. In Example #2, the MIDINIT column will not be matched but since it is in the index it may be screened. This means that while some index entries will be examined that do not qualify, Db2 will not need to go to the tablespace for any row that does not meet all 3 conditions. A more ideal index for this query would invert the last 2 columns so that all 3 could be matched.
The third example uses a column that is in our index but is not the leading column. The index may be used in this less than ideal situation but at a cost. The non-leaf levels of the index will be ignored in this situation and every leaf page will be examined to identify the qualifying rows.
It’s important to remember that all of the above scenarios are possibilities that the Db2 optimizer has at its disposal. They may be chosen or passed over if better options exist. Some factors that Db2 evaluates are:
- Other potential available indexes
- The size of both index and tablespace
- The estimated size of the result produced by each predicate
- The available hardware (cpus, bufferpools, etc)
We’ll discuss more scenarios in future articles later this month. Stay tuned!