Why is Ingest into Db2 Warehouse faster with Cloud Object Storage?
Written by Kostas Rakopoulos, Hamdi Roumani, and Christian Garcia-Arellano
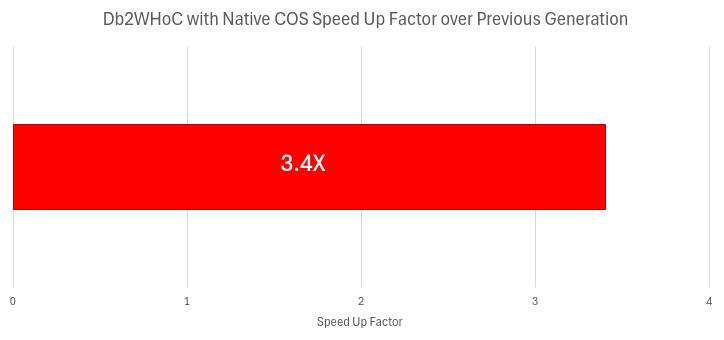
In the journey of adding Cloud Object Storage (COS) support to Db2 Warehouse, the primary motivation was reducing the storage cost (a dominant factor in any warehouse environment) by transitioning to a more modern storage architecture that primarily used COS. This allows us to deliver a 34X storage savings over traditional network-attached block storage. In terms of performance, the expectations were that it would achieve comparative performance with traditional network-attached block storage. However, as highlighted in our preceding blog entry, the resulting query performance was significantly better, which became a prominent achievement of the new generation of Db2 Warehouse. In this blog, we intend to start to walk you through some of the changes we made to the storage layer to also achieve faster ingest performance. Since bulk ingest is one of the most critical ingest use cases in data warehouses, as it plays a pivotal role in efficiently loading very large volumes of data, we will focus this first blog solely on it. In a subsequent blog we will discuss the other important ingest scenario of trickle feed, which is the basis for continuous streaming of data into the data warehouse and it is the enabler of real-time analytics. In the next section we will start with some background on existing optimizations that have been part of Db2 Warehouse for a few releases, but that provide the foundation to understand the optimizations developed in the multi-tier storage layer that supports COS. Then after that, we will dig into the handling of bulk ingest that enables us to deliver over 3X performance improvement over the previous generation of Db2 Warehouse on Cloud. Finally, we will do a more detailed discussion of the performance results we obtained, and the monitoring metrics available to explain the behavior of the multi-tier storage layer in these scenarios.
Bulk writes for Column Organized Tables
Many optimizations have been developed since the introduction of column organized tables in Db2 Warehouse. In the case of large bulk insert transactions, the initial design accounted for high insert parallelism through the introduction of insert ranges into the tuple sequence number (TSN) address space. Insert ranges allowed many parallel insert threads the ability to create pages at the end of its assigned range without contention and into contiguous extents with contiguous pages. This however still required all changes made by transactions to follow the traditional approach of writing them to a write-ahead log (WAL), which becomes a limiting factor for large insert transactions as not only their size is limited by the amount of available active log space, a finite resource, but also due to the significant cost of logging every change, which is mainly in the form of a large number of new pages. In order to overcome these limitations, Db2 introduced an optimization for bulk insert transactions that reduces the log space demands by replacing the redo and undo page level log records for columnar data page writes with extent level log records that do not include the contents of the page changes. In the case of undo log records, fewer undo log records eventually lead to fewer potential compensation log records during recovery, fewer compensation log records lead to a lower amount of reserved log space, and a lower amount of reserved log space ultimately reduces the overall active log space demands of a transaction. In addition to that, the implemented design significantly accelerates rolling back large insert statements. In the case of redo log records, to accomplish durability without a WAL to replay, a different flushing strategy is applied. Specifically, all data pages modified by a given transaction utilizing reduced logging are flushed from the buffer pool to database storage no later than commit of that transaction (usually referred to as “flush-at-commit”). Although on-line backup (OLB) relies on redo log records being written to the Db2 write-ahead-log in order to restore to a transaction-consistent state, the approach taken supports on-line backup and restore to a transaction-consistent state at "end of backup" time through the introduction of a two-phase termination approach for OLB that minimizes the number of log records that are written and still maintains the ability to restore the database from the online backup with minimal replay.
Refresher on the Multi-Tiered Storage Architecture within the Db2 Engine
As we discussed in our previous blog, the new multi-tiered storage architecture introduces a Tiered LSM Storage layer which replaces the I/O access layer used for writing and reading data pages. As you can see in the diagram below, this Tiered LSM Storage layer sits below the buffer pool and table space layers, which are the two components responsible for the management of the in-memory cache and on disk organization of the data pages that form the database.
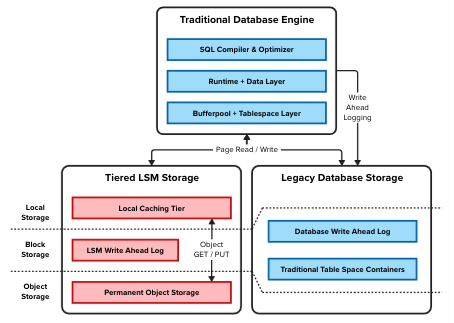
Figure 1 Integration of the LSM storage layer
In this new layer there are three persistence components shown in the diagram:
- Local Caching Tier (Ultra-Low Latency): this tier is used to cache a subset of frequently accessed objects from cloud object storage. This is stored in locally attached NVMe drives in order to mitigate the high latency involved with repeated object storage access. This tier is considered volatile storage and is used both for transient staging during IUD, and as a cache for reads.
- Local Persistent Storage Tier (Low Latency): block storage is used for storing data that is very sensitive to latency, including the remote storage tier write-ahead-log and metadata files.
- Remote Storage Tier (High Latency): COS provides the foundation to achieving one of the primary objectives of reducing the cost of storing large volumes of data, and for that reason, it is used as the main persistent storage layer for the table spaces.
The simplest ingest path through this new storage layer that organizes the data into an LSM tree structure utilizes in-memory write buffers (WBs) to form Sorted String Tables (SSTs) that will be asynchronously written to COS in Level 0 of the LSM tree. To ensure immediate durability, this also uses the LSM write-ahead-log (WAL) as the primary persistence location. Using the WAL allows us to safely make writes to the remote storage tier asynchronous. This results in the data being written twice, once to the WAL and once to COS, but with the advantage of the WAL writes being sequential writes to a traditional storage subsystem, which will exploit the low latency advantages of this storage, and then eventually to cloud storage, which allows the optimization of the block size used to amortize the increased latency. One implication of choosing this write path is the subsequent write amplification because of the need to compact the SSTs that are ingested at the top of the LSM tree. This compaction is necessary to optimize the LSM tree for better access times during reads. Another implication of this write path is the serialization of ingestion through the WAL, which reduces the maximum throughput that can be achieved.
Integrating bulk writes into the LSM Tree Storage Layer
With the introduction of the LSM tree storage layer, the reduced logging transaction mode described before opened the opportunity for an additional optimization of the multi-tier storage layer ingest path which enables us to ingest a large number of data pages in a single batch operation. The key to the optimization is the exploitation of direct ingestion of SSTs into the lowest level of the LSM tree. This direct ingestion is made possible by a bulk loading API provided by the RocksDb implementation that is integrated into the engine to power the LSM storage layer. This allows us to bypass the RocksDb WAL and ingestion into Level 0 of the LSM tree. The latter helps avoid compaction operations which would result in extra cost due to the write amplification. For this optimization to be implemented there are two requirements that must be met. First, clustering keys for the data pages included in a batch must be inserted into a batch in a strictly increasing order, as otherwise this would break the ordering requirement of any level higher than 0 within the LSM tree. Second, in order to maintain the efficiency achieved with this optimization, it should attempt to minimize overlap between the key range within the batch and any existing entries at any level in the tree, in particular, with any concurrent writes that utilize the normal ingest path through write buffers, in order to avoid the flush of the write buffers to maintain the consistency of the LSM tree. In order to satisfy the ordering requirements to apply the optimization we relied on the pre-existing append only I/O patterns for column organized pages when doing large insert operations: the large volume of page writes is parallelized across multiple asynchronous traditional Db2 buffer pool page cleaners, and each page cleaner is assigned contiguous insert ranges of page identifiers that can be batched together in a single optimized write batch. Figure 2 illustrates the multiple page cleaners, each with its own dirty page lists and asynchronous I/O page lists, and each being able to perform the I/O for each insert range through a write batch into the LSM storage layer that is specific to that insert range, ensuring a contiguous range of clustering page identifiers. With this, the generation of the SST files is done in parallel and asynchronously in a staging area in the local caching tier. Once ready, each SST file is uploaded to object storage. During the final flush-at-commit processing we trigger and wait for the page cleaners to upload any pending SST files that have not yet been finalized. Note that only the generation of the SST files is done in parallel, the actual addition to these to the RocksDb metadata through the update of the manifest is a serial operation.
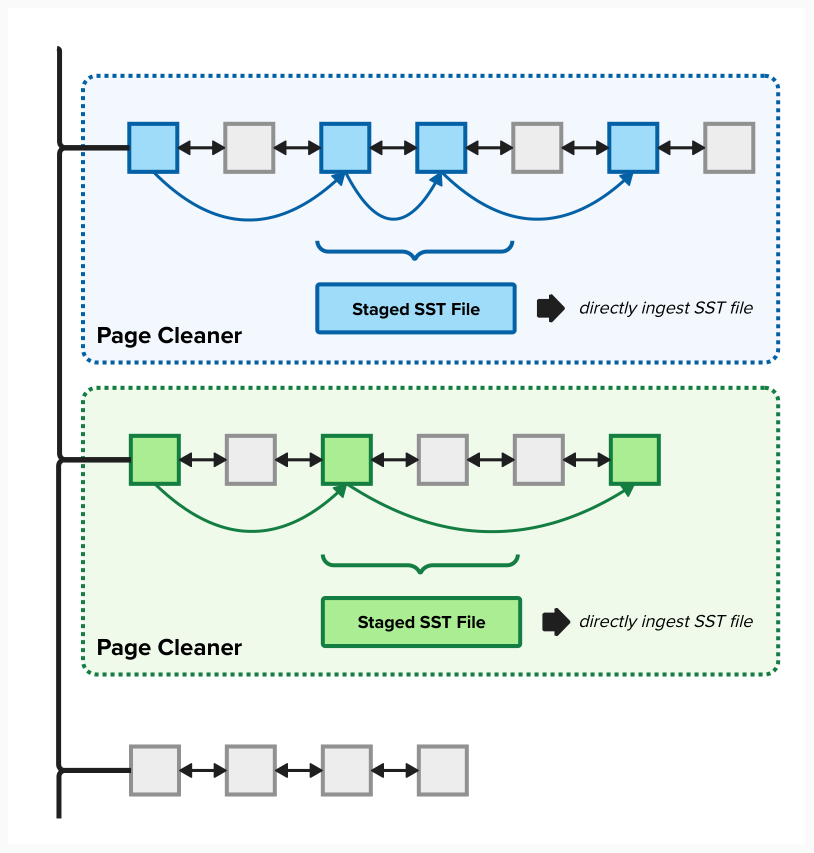
Figure 2 Parallel Page Cleaning using Optimized KF Batches
Performance Results
To measure the impact of our optimization strategy for bulk writes, we used as a benchmark, the time to populate the STORE_SALES fact table of the industry standard TPC-DS benchmark. Specifically, we ran an INSERT FROM SUBSELECT where the source table is the 5 TB scale factor size of the STORE_SALES table which translates into a table with about 14.4 billion rows and an uncompressed size of about 2.3 TB. As our baseline, we used the pre-optimized write code path, the same code path used for writes that do not meet the threshold for the bulk writes optimization code path. The results of our experiments are summarized in the following table.
|
Insert Type |
Elapsed Time (seconds) |
Writes (GB) |
|||
|
Local Tier |
Caching Tier |
Remote Tier |
Compaction |
||
|
Pre-Optimized |
1,360 |
465 |
3,161 |
467 |
2,693 |
|
Bulk Optimized |
238 |
5 |
468 |
465 |
3 |
|
Benefit from Optimization (%) |
82 |
98 |
85 |
0 |
99 |
From an end-to-end execution time perspective, the elapsed time improvement over the pre-optimized insert is massive. We measured an 82% reduction in elapsed time as a result of using the bulk optimized code path. We can dig into this further using our new Native COS monitoring elements which include the following. Note that for the metrics below, we also have associated metrics for bytes written as well as time spent writing.
- LOCAL_TIER_WRITE_REQS
- The number of write requests to the Local Persistent Storage Tier which is used to hold the RocksDb WAL.
- CACHING_TIER_WRITE_REQS
- The number of write requests to the Local Caching Tier which is used for both caching reads from COS as well as staging writes to COS
- REMOTE_TIER_WRITE_REQS
- The number of write requests to the Remote Storage Tier (COS). This excludes writes to COS that are due to compaction.
- COMPACTION_WRITE_REQS
- The number of writes to COS that occur during compaction.
Looking at the monitoring metrics specific to the storage tiers we discussed above, we can see the benefits of using direct ingestion into the LSM. To start, we see the bulk optimized writes effectively eliminate the need to do Local Tier writes as measured by a 98% reduction in the number of bytes written to the Local Tier. Recall from above, the Local Tier is where the RocksDb WAL is located and that direct ingestion into the LSM before the transaction can be considered committed, allows us to bypass the WAL. As for COS writes, our monitoring breaks these up into writes due to compaction and all other writes. With this benchmark being a pure INSERT transaction, all other writes are SST file uploads. Starting with Remote Tier writes, which are the number of bytes written to COS (excluding compaction writes), we measure no benefit here. No benefit is expected since our bulk optimized writes must still adhere to ACID transaction properties and so we must ensure durability by writing all the data to COS by the end of the transaction. Looking at Compaction Tier writes, we measured a 99% drop in the number of bytes written to COS due to compaction. Like we were able to effectively eliminate Local Tier writes, direct ingestion of SSTs into the lowest level of the LSM tree makes compaction of these SSTs unnecessary. The compaction process also requires writing to our Caching Tier (to create the compacted SST files before they are uploaded to COS). As a result, the elimination of compaction also reduces our Caching Tier bytes written by 85%. Note that the Caching Tier is still utilized during bulk optimized writes to create the SST files that will be directly ingested into the LSM.
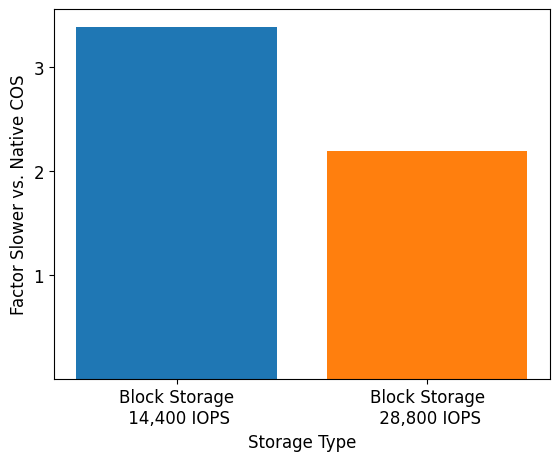
We also compared the performance of our bulk optimized writes for Native COS tables to the previous Db2 Warehouse on Cloud release which did not support COS tables and instead used block based, network-attached storage. The benchmark was the same INSERT FROM SUBSELECT as described above but, in this case, the source and target tables had their storage on either COS or block storage. As our baselines, we tested with two types of block storage, one with the default 14,400 IOPS and the other with twice the default, 28,800 IOPS. We found the performance of Native COS tables to be several factors higher than that of tables using block storage. At the heart of the performance improvement realized with Native COS tables is our use of the Caching Tier to stage writes before they are hardened to COS (we avoid crossing the network for each individual page write), as well as the higher bandwidth we achieve with COS compared to block storage. The latter is critical for the performance of INSERT FROM SUBSELECT for Native COS tables. This is because we are able to prefetch and cache the source table data in our Caching Tier, which is significantly larger than the in-memory buffer pool (cache) that block storage tables are limited to. We also found the latency of the network-attached block storage started to degrade significantly as we approached the IOPS capacity of the volumes, as expected.
Conclusion
The new release of Db2 Warehouse on Cloud in AWS introduced the support of Cloud Object Storage as a storage medium for the database, which enabled not only the massive 34X storage savings over the traditional network-attached block storage, but also as we’ve seen, unleash new performance boundaries due to the innovative multi-tier storage architecture. In this post, we dig further into the technology that powers these achievements, this time focusing on bulk ingest, one of the most critical ingest use cases in data warehouses to allow it to efficiently ingest very large volumes of data at once. In a future post, we will discuss some other ingest performance optimizations that were developed in order to enable the continuous ingestion of data and open the door to real-time analytics, another of the key use cases of data warehouses.
About the Authors
Kostas Rakopoulos is a member of the Db2 Performance team at the IBM Toronto Lab and has a BSc in Computer Science from the University of Toronto. Since joining the Db2 Performance team in 2008, Kostas has worked on a wide range of Db2 offering types including Db2 pureScale (OLTP), Db2 Event Store (IoT) and Db2 Warehouse. Most recently, Kostas has been working on the Native Cloud Object Storage feature in Db2 Warehouse. Kostas can be reached at kostasr@ca.ibm.com.
Hamdi Roumani is a senior manager of the Db2 COS team, overseeing Db2's native cloud object storage support and the columnar storage engine. With extensive experience at IBM, Hamdi began his career on the availability team as a developer, contributing to numerous enhancements for Db2's backup, restore, and write-ahead logging facilities. He then transitioned to the newly formed IBM Cloud IAAS team, where he focused on building the next-generation platform layer, specifically the storage layer (object and block storage) and the monitoring framework used for billing. Recently, Hamdi returned to Db2 to work on the next-generation warehouse engine. He can be reached at roumani@ca.ibm.com.
Christian Garcia-Arellano is Senior Technical Staff Member, Master Inventor and lead architect in the DB2 Kernel Development team at the IBM Toronto Lab and has a MSc in Computer Science from the University of Toronto. Christian has been working in various DB2 Kernel development areas since 2001. Initially Christian worked on the development of the self-tuning memory manager (STMM) and led various of the high availability features for DB2 pureScale that make it the industry leading database in availability. More recently, Christian was one of the architects for Db2 Event Store, and the leading architect of the Native Cloud Object Storage feature in Db2 Warehouse. Christian can be reached at cmgarcia@ca.ibm.com.