Comparing the Performance of Db2 12.1 vs. PostgreSQL
By Kostas Rakopoulos and Christian Garcia-Arellano
IBM’s Db2 database is a long-time heavyweight in the database market that runs many of the world’s mission critical workloads. Built to support both high performance transactional and real-time analytical workloads, Db2 provides a unified platform for database administrators (DBAs), enterprise architects and developers to run apps, store and query data, and deliver enterprise grade data management capabilities.
One of the domains where Db2 excels is running business critical transactional workloads. It’s well known that Db2 provides the functionality, reliability, and performance required for high scale OLTP workloads, but in today’s world it’s fair to ask how it stacks up against its open-source counterparts. Popular open-source databases like MySQL, and increasingly PostgreSQL, in recent years have achieved significant traction in the database market due to their ubiquitous accessibility.
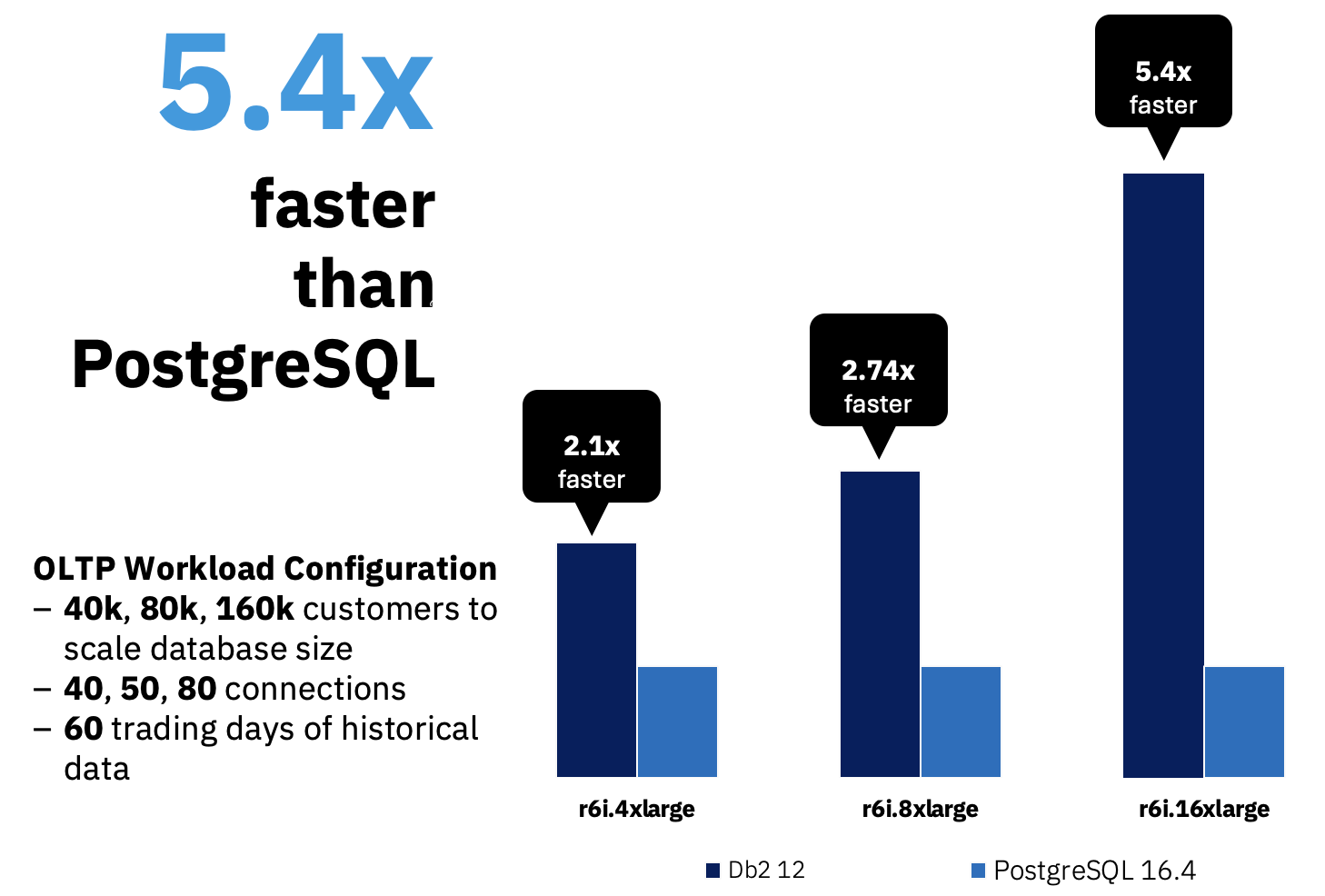
As part of the release for Db2 12.1 in November 2024, we decided to put it through its paces against PostgreSQL using a transactional workload based on the TPC-E benchmark, and choosing AWS EC2 cloud environments to level the field, running at various scales. There were many discoveries with this effort, but the main result was that not only Db2 was faster at all scales, up to 5.4X faster, but also that it scales better than PostgreSQL.
In this blog, we are going to discuss the details of the effort to get to these results. In the next sections we start discussing the workload we used, followed by the environment, then the databases, and finally the test results.
The Workload
Let’s start with the workload. Like we said, the goal here was to validate the transactional performance of Db2 12.1 relative to PostgreSQL. We looked at several well-known Online Transaction Processing (OLTP) workloads, and we decided on using a workload based on TPC-E because it is a modern and complex workload with a high write ratio that is well known in the industry. This workload implements a brokerage system with pre-existing operational data, mimicking a real-world environment where transactions are not starting from scratch but rather building on days of prior activity. In this effort, we chose the best available kit for each of the two databases as a base in order to reduce the implementation bias from the comparison: for PostgreSQL we used the DBT-5 kit, and for Db2 we used our own internal implementation of the TPC-E kit, internally named DTW2. [1]
In order to ensure equivalency in the comparison, we made three changes to the kits:
- Seed Data: to ensure that both kits were able to use the same data files for seeding the database,
- Schemas: to ensure we used the same database schemas on both sets of runs. This included adding some indexes that were not present in the PostgreSQL kit, and also adding INCLUDE clauses to some of the indexes. We note here that when running workloads based on TPC-E there is no requirement or suggestion on the indexes to use, so it is up to the implementer to decide the best indexes. In particular, there were two indexes on the TRADE table not present in the DBT-5 kit that made most of the difference to improve PosgreSQL’s performance (one on t_ca_id, t_dts, and the other one on t_s_symb, t_dts), increasing the performance in the PostgreSQL runs over 2X.
- Database Scale: to ensure that the environments where balanced in terms of CPU and IO we experimented with the Initial Trade Days parameter to scale the database and settled on using 60 ITD instead of 300 ITD that is commonly used for TPC-E runs (more on this in the Database Scale section).
DBT-5 TPC-E Kit
The DBT-5 TPC-E kit is a fair-use, open-source implementation of the TPC-E benchmark specification that has been written by EnterpriseDB (EDB), one of the largest contributors to PostgreSQL development. The DBT-5 kit supports three modes of execution for the workload:
- Stored procedures written in PL/pgSQL (default)
- Stored procedures written in C
- Client-side logic written in C++
We experimented with all three of these modes of execution and found stored procedures written in C to be the fastest. In regard to the other two, the client-side logic requires more client-server interaction and this additional latency resulted in lower throughput, and the stored procedures written in PL/pgSQL were found to be very slow (more discussion on this later on).
The only change of significance we made to the DBT-5 kit was to address a performance issue due to lock contention in its implementation of the Market Exchange Emulator (MEE). This resulted in only one Trade Request transaction being in-flight at a given time per MEE process, which caused a big drop in performance because the TPC-E throughout is measured by the number of Trade Request transactions completed per second (TR/s). The change we made was to start an MEE process per user, thus ensuring each user could be concurrently executing a Trade Request transaction with other users.
Db2 DTW2 TPC-E Kit
The DB2 DTW2 kit is an IBM-internal implementation based on the TPC-E specification. The Db2 implementation supports two modes of execution for the workload:
- SQL stored procedures using array types
- SQL stored procedures using non-array types
For our tests, we used the SQL stored procedures with array types as it is the one that performs the best, and it is available in all environments where Db2 runs.
Database Scale
In terms of database scale, we used 2,500 customers per vCPU (virtual CPUs) as this was a reference number we internally used for similar workloads for the relatively high latency (network attached) storage in cloud environments. Since our base (small) compute size has 16 vCPUs, we decided to use 40,000 customers for that scale. One of the database parameters of the workload is Initial Trade Days (ITD), which represents the number of days of historical trading data preloaded into the database before the test begins. When we run at that scale and using 300 ITD, we observed that both databases were heavily IO bottlenecked (30% CPU utilization and 63% IO wait in the case of Db2). In order to improve the balance, we could have either reduced the number of customers per core, reduced the ITD or increased the memory. We first tried reducing the number of ITD and ended up with a value of 60 (1/5) that showed the most balanced scale for both environments, fully consuming the CPU and not overloading the I/O subsystem, so we decided to keep the ITD constant at this value as we scaled. As we scaled up the compute for our medium (2x) and large tests (4x), we scaled up the database size by increasing the number of customers to 80,000 and 160,000 respectively, maintaining the same ratio, and we observed the balance remained.
The Environment
Like we said in the introduction, we chose AWS EC2 as the level field for this validation, using instance types that are available both for AWS RDS for PostgreSQL and AWS RDS for Db2. We deployed these environments, installed each of the databases, and used as a starting point the corresponding AWS RDS configuration for each with minimal changes that we will discuss in the subsequent sections.
Amazon EC2 Instance Types Used
For the database servers, we used the three different sizes of Amazon EC2 Memory Optimized R6i instances listed in the following table:
|
Config |
Instance Type |
vCPUs |
Memory (GiB) |
Network (Gbps) |
|
Small |
r6i.4xlarge |
16 |
128 |
Up to 12.5 |
|
Medium |
r6i.8xlarge |
32 |
256 |
12.5 |
|
Large |
r6i.16xlarge |
64 |
512 |
25 |
For the client system, we used the following Amazon EC2 General Purpose M6i instance:
|
Instance Type |
vCPUs |
Memory (GiB) |
Network (Gbps) |
|
m6i.2xlarge |
8 |
32 |
Up to 12.5 |
Amazon EBS Storage Used
We used Amazon’s top tier of EBS storage, the Provisioned IOPS SSD (io2) Block Express Volumes for our database storage. As with compute, we also scaled the EBS volume size and IOPS as shown in the following tables. Note that we also used dedicated log volumes as it is a best practice to ensure adequate database write-ahead log performance, both for Db2 and PostgreSQL. For our data volumes, we used four volumes in a striped LVM setup. The following tables show the number, sizes and IOPS configured for each.
Data Volumes
|
Config |
Volumes |
Volume Type |
Total Size (GB) |
Total IOPS |
|
Small |
4 |
EBS io2 |
2000 |
8000 |
|
Medium |
4 |
EBS io2 |
4000 |
16000 |
|
Large |
4 |
EBS io2 |
8000 |
32000 |
Log Volume
|
Config |
Volumes |
Volume Type |
Total Size (GB) |
Total IOPS |
|
Small |
1 |
EBS io2 |
1000 |
1000 |
|
Medium |
1 |
EBS io2 |
1000 |
2000 |
|
Large |
1 |
EBS io2 |
1000 |
4000 |
The Databases
Db2
For Db2 we used version 12.1. In the Db2 managed environments, both Db2 on Cloud in IBM Cloud and Amazon RDS for Db2 we use the Self-Tuning Memory Manager (STMM) by default. STMM is an autonomous control system that has been in Db2 for almost 20 years, and which continuously adapt the configuration to the workload changes and enables the configuration to be hands-off. Since in these tests we wanted fully repeatable results, instead we fixed the configuration, mainly the buffer pool memory and sort memory, in order to eliminate run variations due to the continuous tuning. The configuration that we used was fixing the single buffer pool to 80GB, 160GB and 320GB for the small, medium and large environments respectively, and the sort memory configuration parameter SHEAPTHRES_SHR was fixed at 5000 pages for all 3 configurations.
PostgreSQL
For PostgreSQL we tested both versions 16.4 and 17. We started with version 16.4 because that was the version supported by Amazon RDS for PostgreSQL. We also decided to test version 17 because it was released around the same time as we were running these tests and the release notes had claims of improved performance. This however did not materialize in our tests with TPC-E, where we observed that relative to PostgreSQL 16.4, it was 13%, 8% and 17% slower at the small, medium and large scales respectively. For this reason, we decided to continue with the testing using version 16.4.
In terms of configuration, we based the core of the configuration on the one used in Amazon RDS for PostgreSQL, as we expect this to be optimally configured. The main change we had to make to maximize performance was in the value of the shared_buffer parameter. This parameter controls how much memory is available to cache data being read and written in the database. However, PostgreSQL, unlike Db2, does not use direct IO, which results in any data read and written is also cached in the operating system’s file system cache. This results in double buffering which hurts the internal database cache efficiency. The default Amazon RDS for PostgreSQL shared_buffer setting is 30 GB on the small size compute (23% of 128 GB system memory), which is in line with the general recommendations of setting this to somewhere between 15 and 25%. In our tests with TPC-E, we found it was better to reduce the shared_buffer size from 30 GB down to 3 GB at the small scale. We scaled the shared_buffer parameter as we scaled up the compute size. It is also worth noting that when we also experimented with larger shared_buffer sizes than the recommendation, and we also tested with huge pages enabled and disabled. In both cases, we found that with a smaller shared_buffer size we were able to achieve the best performance for this workload, so that is what we used for our comparison with Db2.
The Tests
For TPC-E, performance is reported as a Trade Results per second (TR/s). The Trade Result transaction is one of several transaction types in the TPC-E kit. This means the TR/s number is not indicative of total commits/second. Since the intent of this work is to show the relative performance of Db2 with respect to PostgreSQL, we will report all performance as based on the relative TR/s.
Db2 in AWS
Initial runs at the medium system size showed an access plan issue regarding the TRADE_REQUEST table. This table starts out empty and grows and shrinks during the run as trade requests are generated and completed. The table statistics used by the Db2 optimizer are collected after database population when the TRADE_REQUEST table is empty, and this leads to an inefficient access plan for this table. In a normal customer environment, this would be resolved with the automatic statistics collection available in Db2, part of the Db2 automated table maintenance feature that automatically manages the object statistics without any user intervention, and that is able to collect real-time statistics. In addition, Db2 v12 also released the AI Query Optimizer, that has the ability to generate AI models to improve the cardinality estimation. In this case, since it is a short-lived workload, we used an alternative way to deal with this exact scenario through the use of the VOLATILE flag using an ALTER TABLE statement. This informs the optimizer to not rely as heavily on the current table statistics, which works best for these short-lived workloads and is also successfully exploited in customer environments with highly volatile data distributions. The runs discussed below all use the VOLATILE flag for the TRADE_REQUEST table.
This first table shows the results using 60 ITD, which is what we used to compare Db2 with PosgreSQL. The relative TR/s in the table are relative to the result obtained when running with the small configuration.
|
Config |
Relative TR/s |
Database %CPU |
Database %IOWAIT |
Database Data IOPS |
|
Small |
1.00X |
98% |
1% |
85% |
|
Medium |
1.76X |
93% |
0% |
88% |
|
Large |
2.67X |
92% |
2% |
89% |
Like we discussed previously when we introduced the database scale, we initially did runs with 300 Initial Trade Days (ITD). The table below shows the relative performance using 60 ITD vs 300 ITD, showing that with 60 ITD it is always at least 2X faster than with 300 ITD, and we also show the significant IO wait and low CPU utilization we observed. In these cases, when we looked at the data disk IOPS we saw that we were very close to the EBS volume limits. In the case of the log volume IOPS, in all three configurations we were well below the 3000 IOPS limit and our log disk latency was under 0.5 milliseconds. The disk IO bottleneck was entirely on the data volumes. We also experimented with compression to change the balance, but that was not sufficient to compensate for such a difference.
|
Config |
TR/s relative to 300 ITD |
Database %CPU |
Database %IOWAIT |
|
Small |
2.15X |
30% |
63% |
|
Medium |
2.07X |
26% |
57% |
|
Large |
2.03X |
25% |
50% |
PostgreSQL in AWS
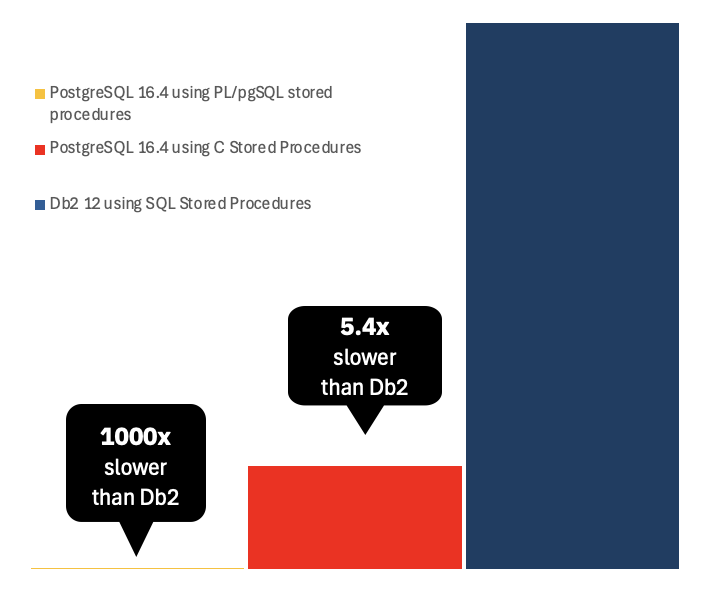
As we said, the initial runs we did on PostgreSQL with the DBT-5 kit’s default PL/pgSQL stored procedures were very slow, throughput was always less than 1 TR/s, which ended up being 200X slower than our final number (this was the case for both 300 and 60 ITD), and 1000X slower than Db2. Some investigation suggested that the PL/pgSQL stored procedures could be problematic for the optimizer which could lead to poor access plan choices, which lead us to try with the other two modes in the DBT-5 kit. In these tests we noticed that we could increase the throughput by over 150X by running without stored procedures (even after the client-server latency that this adds), and when running C stored procedures, the throughput increased even further to about 200X over PL/pgSQL stored procedures. This chart summarizes these results:
Like with Db2, the PostgreSQL was under configured and unrealistic for running with 300 ITD, so we focused on 60 ITD. The following are the results for PostgreSQL 16.4 at 60 ITD:
|
Config |
Relative TR/s |
Database %CPU |
Database %IOWAIT |
Database %IOPS |
|
Small |
1.00 |
98% |
1% |
95% |
|
Medium |
1.37 |
96% |
2% |
98% |
|
Large |
1.06 |
98% |
0% |
75% |
At the large-scale PostgreSQL barely matches the performance it is able to achieve at the small scale. With CPU usage being so much higher at the large scale with no increase in throughput, it seems as though one or more of the query access plans changed causing less efficient use of the CPU. For example, because of the poor plan, the engine is now having to process a lot more rows and this is driving up the CPU usage. One stored procedure we noted was problematic was SecurityDetailFrame1, as we observed that it takes 4.8x longer to execute at the large scale compared to small, so it seems to scale linearly with the increase in data volume, but we did not do further investigation on it.
Like we said, we also tested PostgreSQL 17.0 once it was released with similar scalability behavior:
|
Config |
Scalability |
Database %CPU |
Database %IOWAIT |
Database IOPS |
|
Small |
1.00 |
67% |
10% |
100% |
|
Medium |
1.45 |
97% |
2% |
100% |
|
Large |
1.00 |
99% |
0% |
63% |
Relative to PostgreSQL 16.4 we found version 17.0 to be 13%, 8% and 17% slower at the small, medium and large scales respectively when using the same configuration. One thing that we found interesting in these runs was that there was a drop in log disk writes per second (indicative of a drop in throughput) near the end of the run, and during these spikes in writes per second, % IOWAIT increased from 5% to 20%.
Conclusions
In this blog, we discussed the work we did to fairly compare the performance of PostgreSQL with Db2 on transactional workloads. As we showed, Db2 12.1 not only beat PostgreSQL handily in performance running on the same hardware in AWS, but it also demonstrated that the performance gap increases as the database system is scaled up, showcasing a 5.4X performance advantage at the largest scale we tested, and with this gap widening for higher scales (Db2 is 2.1X faster than PostgreSQL at the small scale, and 2.74X faster at the medium scale). This highlights the advantage of leveraging Db2’s strong performance for your transactional workloads, and how Db2’s advantage becomes more pronounced as the scale grows. Db2 is a database that is used to run the world’s mission critical workloads, at significant greater scales than the ones shown here, and with the ability to continue scaling even further when exploiting the pureScale active-active feature. This work just demonstrates the advantage of an enterprise level database like Db2 even at these relatively small scales.
About the Authors
Kostas Rakopoulos is a member of the Db2 Performance team at the IBM Toronto Lab and has a BSc in Computer Science from the University of Toronto. Since joining the Db2 Performance team in 2008, Kostas has worked on a wide range of Db2 offering types including Db2 pureScale (OLTP), Db2 Event Store (IoT) and Db2 Warehouse. Most recently, Kostas has been working on the Native Cloud Object Storage feature in Db2 Warehouse. Kostas can be reached at kostasr@ca.ibm.com.
Christian Garcia-Arellano is a STSM and Db2 OLTP Architect at the IBM Toronto Lab, and has a MSc in Computer Science from the University of Toronto. Christian has been working in various DB2 Kernel development areas since 2001. Initially Christian worked on the development of the self-tuning memory manager (STMM) and led various of the high availability features for DB2 pureScale that make it the industry leading database in availability. More recently, Christian was one of the architects for Db2 Event Store, and the leading architect of the Native Cloud Object Storage feature in Db2 Warehouse. Christian can be reached at cmgarcia@ca.ibm.com.
Footnotes
[1] The DBT-5 and DTW2 implementations are derived from the TPC-E benchmark and as such are not comparable to published TPC-E results, as the DBT-5 and DTW2 implementations do not fully comply with the TPC-E specification.