Integration of Cloud Object Store in an IBM Cloud for Db2 Database Recovery
by Boris Stupurak IBM Research & Development

Storage systems play an important role in database recovery. Since storage capabilities are one of the central characteristics of cloud environments. This is why database products learn to make use of cloud features to store backups and database log archives.
Within this blog we will look at the integration of cloud object store (COS) of an IBM Cloud into a Db2 landscape to store backup images and logfile archives. I consider Db2 environments of level 11.5.7.0 or higher. To access and view cloud content IBM Cloud CLI is used..
All concepts described within this document can also be used for AWS cloud.
Terminology
First we want to become familiar with the most basic terminology:
- In IBM Cloud Object Storage, a bucket is a kind of container. Buckets are not nested, i.e. a COS bucket does not contain other buckets.
- Data is stored as COS objects. Object names can include slashes so that the naming often look like a UNIX filesystem structure. However, unlike a filesystem, COS objects have no hierarchy.
Configuration
To be able to work with the cloud, you need to setup the access. Actual levels of Db2 LUW allow to use the S3 API to work with COS. A Db2 instance works with a COS instance using the following resources:
- a keystore to keep access data for the COS account
- account credentials for the COS instance
You can use a local keystore:
https://www.ibm.com/docs/en/db2/11.5?topic=keystores-creating-local-keystore
or a centralized keystore:
https://www.ibm.com/docs/en/
For cloud access the Amazon S3 API appears to become a standard. Db2 LUW allows the use of this API. However, to authenticate using the S3 API you need to create a key pair consisting of an access key and a secret key. This key pair is known as HMAC credential. The procedure to create a HMAC credential is well described in:
https://cloud.ibm.com/docs/cloud-object-storage?topic=cloud-object-storage-uhc-hmac-credentials-main
Cloud Access
Using a local keystore the Db2 instance needs to be configured making updates to the DBM CFG with location and keystore type:
db2 update dbm cfg using keystore_location <path of the keystore file>
db2 update dbm cfg using keystore_type pkcs12
Then a restart of the Db2 Instance is required.
The next step is to catalog the cloud storage location using the following command:
db2 catalog storage access alias <alias name> \
vendor s3 \
server … \
user … \
password … \
[container <COS bucket name> [object <object name>]]
The alias name you use within this command is of your choice. The required connection data consist of the remote location (the server entry), and the credentials (user/password). You can get this data listing the HMAC credentials for your COS instance. List available service keys using the following command.
ibmcloud resource service-keys

Then use the key name of the HMAC credential you created, and run
ibmcloud resource service-key <key name>
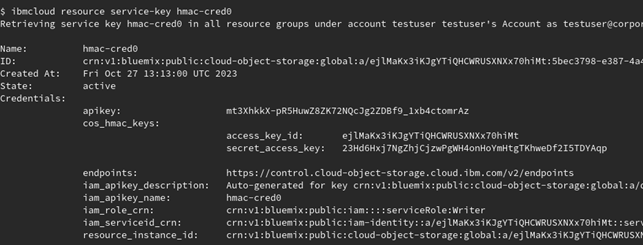
The access_key_id and secret_access_key under cos_hmac_keys indicate each the entries for user and password.
The credential listed as endpoints is a URL containing a list of possible server locations. You have to use one of these server locations to specify the server parameter.
Using the create storage access command you define an alias that refers to the COS objects. The parameters container and object are optional and allow to specify, as part of the alias, a COS bucket and a prefix for object names. The benefit of these will show-up within the next section.
Location Identifiers
Now with an existing alias, it would be interesting to know how to use it inside Db2 to access a COS location.
To demonstrate this, create alias myalias to point to your COS instance:
db2 catalog storage access alias myalias \
vendor s3 \
server https://control.cloud-object-storage.cloud.ibm.com/v2/endpoints \
user ejlMaKx3iKJgYTiQHCWRUSXNXx70hiMt \
password 23Hd6Hxj7NgZhjCjzwPgWH4onHoYmHtgTKhweDf2I5TDYAqp
As a prerequisite to store data in a COS instance, you have to create a container called
a bucket. You can create a bucket with name mybucket using the command below.
ibmcloud cos bucket-create –bucket mybucket
To work in Db2 LUW with objects in bucket mybucket, you use a location identifier as follows:
DB2REMOTE://myalias/mybucket/myobject
Db2 LUW is using the object part of the location identifier (myobject in this example) as prefix for the COS object names. In fact, this terminology requires some clarification. When we talk about location identifiers of Db2 LUW, the object information denotes a prefix. In COS terminology of the IBM Cloud, the object name identifies the object itself. In the examples below I will explain this in detail.
The syntax shown can lead to lengthy location identifiers that are heavy to use in daily operations. But there are options to make the handling of location identifiers a bit more convenient.
If you include the bucket mybucket into the definition of myalias (using keyword container), then the DB2REMOTE identifier used before is still correct.
db2 catalog storage access alias myalias \
vendor s3 \
server https://control.cloud-object-storage.cloud.ibm.com/v2/endpoints \
user ejlMaKx3iKJgYTiQHCWRUSXNXx70hiMt \
password 23Hd6Hxj7NgZhjCjzwPgWH4onHoYmHtgTKhweDf2I5TDYAqp \
container mybucket
You now can leave out the bucket name:
DB2REMOTE://myalias//myobject
The double slash after the alias indicates that the information about the bucket to be used is taken from the alias. If the object name is also specified in the alias definition, the DB2REMOTE identifier can be written as follows.
DB2REMOTE://myalias//
An identifier ending with double slash indicates that even the object name is to be taken from the alias. However, you still can use the former syntax. For example, you can use the alias to access another bucket of your COS instance.
Multipart Upload
To benefit from a better performance it is highly recommended to upload large amounts
of data into COS using a multipart upload. The multipart upload splits the data into several parts uploading them independently and in parallel. You will find a detailed documentation regarding this cloud storage strategy under the following link:
https://cloud.ibm.com/docs/cloud-object-storage/basics?topic=cloud-object-storage-large-objects
The multipart upload is the default within a Db2 LUW installation. The corresponding
Db2 registry setting is : DB2_ENABLE_COS_SDK=ON
To switch off the multipart upload is not recommended.
à https://www.ibm.com/docs/en/db2/11.5?topic=variables-miscellaneous#r0005669__M_DB2_ENABLE_COS_SDK
Within this blog the usage of multipart upload is a prerequisite for all examples.
But also the multipart upload has size limitations. From my point of view these are high enough to store even backups of large database environments.
- maximum number of parts per upload: 10000
- chunk size: 5 MB – 5 GB
- maximum size for an object in COS: 10 TB
In Db2 LUW, the size of the data chunks is configured in the DBM CFG using parameter MULTIPARTSIZEMB. The unit is in megabytes, the default is 100. Corresponding to the IBM Cloud limitations, it allows values between 5, and 5120.
To configure it in the right way, you need to ensure that you stay below the maximum values above. Especially for backups to COS the size limitations hold per backup path. Therefore, you need to
- use multiple backup paths for backup images >10 TB
- set the MULTIPARTSIZEMB parameter to stay <10000 parts per backup path
Staging Area
While Db2 database backups are uploaded directly into the cloud, the Db2 database restore first downloads the data into the staging area. Further restore processing is performed from there.
Logfile archival and retrieval use the staging area in a similar way before data transfer.
By default the staging area is a subdirectory of ~/sqllib/tmp. It can be configured e.g using a different path with the following Db2 registry parameter:
DB2_OBJECT_STORAGE_LOCAL_STAGING_PATH
If you will set this to a value of your choice a restart of the Db2 instance is required
to get the setting activated. Please also see: https://www.ibm.com/docs/en/db2/11.5?topic=reference-remote-storage-requirements
Log Archival and Retrieval
As the COS instance is accessible out of Db2, the database can be configured to
archive the database logfiles into the Cloud. As an example, for logfile archival to bucket mybucket, use the following command:
db2 update db cfg using logarchmeth1 DB2REMOTE://myalias/mybucket/logs
The above command only works when you are connected to the database.
At remote storage, Db2 creates object names similar to the directory structure
of the local file system.
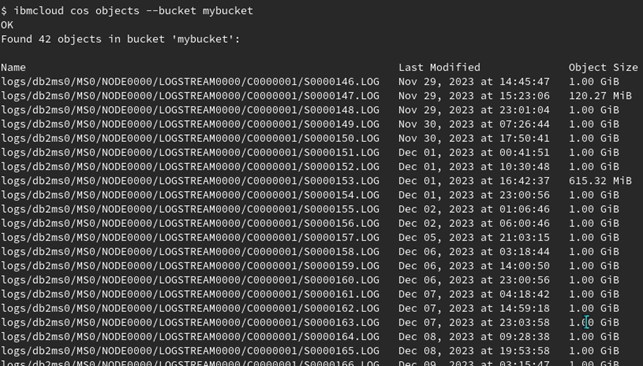
In the specification of the location identifier, we see that the object information is
logs
With the location identifier specified this is the prefix used for all objects stored in COS. The full COS object names identify the individual objects:
logs/db2ms0/MS0/NODE0000/LOGSTREAM0000/C0000001/S0000146.LOG
logs/db2ms0/MS0/NODE0000/LOGSTREAM0000/C0000001/S0000147.LOG
...
Db2 LUW uses the same configuration parameter for logfile retrieval as for the logfile archival. The logfiles are being retrieved to the staging area. From there the staging area the logfiles are being processed further according to the utility requesting the logfile. For example a backup with INCLUDE LOG option, or a ROLLFORWARD operation.
Backup
You have to use the same syntax to perform a backup into a COS instance as in a backup to disk. As a location to store the backup, specify the DB2REMOTE identifiers as shown above. The following example shows the backup goes to a different bucket than the logfiles.
db2 backup db ms0 online to
db2remote://myalias/mybackup/backups/MS0,
db2remote://myalias/mybackup/backups/MS0,
db2remote://myalias/mybackup/backups/MS0,
db2remote://myalias/mybackup/backups/MS0
It is on your choice to define an additional storage alias, e.g myalias2, with bucket mybackup as default. Then, the backup command looks different:
db2 backup db ms0 online to
db2remote://myalias2//backups/MS0,
db2remote://myalias2//backups/MS0,
db2remote://myalias2//backups/MS0,
db2remote://myalias2//backups/MS0
If you also specify the object in the configuration of the alias, you can also omit the part after the last double slash.
db2 backup db ms0 online to
db2remote://myalias2//,
db2remote://myalias2//,
db2remote://myalias2//,
db2remote://myalias2//
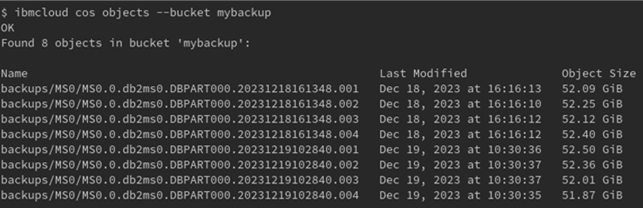
The list below shows you 2 backups in bucket mybackup. Each backup image consists of 4 COS objects. Keep in mind that the sizes of the objects are limited to 10tb.
Remarks
- If DB CFG parameters NUM_DB_BACKUPS, REC_HIS_RETENTN, and AUTO_DEL_REC_OBJ are configured properly, Db2 will automatically delete old backup images including the corresponding logfiles.
- A backup using INCLUDE LOGS, which is the default behaviour, potentially has to restore logfiles from the archive location. When using COS, this works seamlessly.
- The object part of the location identifier is backups/MS0. When the backup has been stored as COS objects, Db2 LUW will take this object part and appends a slash and a string that we would expect from the backup to disk.
Restore
Similar to a backup, the restore from COS works with the same DB2REMOTE identifiers using the syntax of a restore from local storage. In fact, the restore makes use of the staging area being configured. Be aware that the restore downloads the first part of the backup image, i.e. the file of the backup image with sequence number 001, and then starts processing the restore. While the restore is running the Db2 engine downloads the remaining sequences of the backup image in background.
The consequence of the behavior is:
- You need to have the disk space available that is required to hold the backup image to be restored.
- With a smaller size of the sequences of the backup image a restore will start earlier to copy data into the data files. On the other hand, there are also limitations to the number of sequences that are imposed on backup and restore processing by e.g. the amount of prefetcher threads in the Db2 engine, possible I/O bottlenecks due to high processing parallelism, and network throughput into the cloud. It therefore is advisable to start the backup / restore parallelism with similar numbers as in non-cloud environments. If still desired, the effects of higher parallelism can be tested afterwards.
Summary
I’ve shown you how you can set up the backup and recovery of an IBM Db2 for Linux, UNIX, and Windows database to the Cloud. With the procedures I’ve outlined, you can store backup images and log file archives to the cloud object store (COS) of an IBM Cloud. As the approach chosen uses the Amazon S3 API, you can use my examples for the setup of an AWS Cloud as well.
Author
My name is Boris Stupurak. I am an Advisory Development Engineer for IBM Data and AI working over 25 years now with IBM in the SAP on Db2 Development Team from the
IBM Boeblingen Lab. Currently I am working for the SAP Db2 Development Support, supporting customers worldwide running on SAP with Db2 LUW.