Real Time Analytics on High Volume Streaming Workloads with Db2 Warehouse
By Christian Garcia-Arellano, Daniel Zilio and Kostas Rakopoulos
Db2 Warehouse is a transactional database that has been used for decades to implement data analytics solutions, covering the full spectrum from deep analytics to real time analytics. However, more and more, enterprises wishing to gain a competitive advantage are moving the bar higher in their needs to produce more timely insights from ever growing volumes of data, leading to new challenges for Data Warehouses. A usual example of this is the rise of IoT workloads, that generate vast volumes of data from the large volume of devices and sensors, much larger than traditional Data Warehouse use cases, and that require real time analytics to protect enterprises from significant business interruptions through predictive analytics, with the expectation that these will be produced closer and closer to the time the data is generated. IoT is just one example, there are many other use cases that cover similar ever-growing volumes of data beyond IoT, including finance, for example for fraud detection; eCommerce, for example to produce personalized recommendations; or security, for timely detection and response to security breaches. Due to these new challenges, Db2 Warehouse continues to innovate and introduce features that enable enterprises to successfully reach these new heights. In this blog, we focus on some of the features that have been recently introduced in the 11.5 release stream to deliver on these challenges. These include the support of more cost-effective storage of these vast volumes of data with Cloud Object Storage, 34X cheaper than in traditional block storage, and new interfaces to enable continuous ingestion from streaming software like Apache Kafka and enable Db2 Warehouse to reach new ingestion performance heights, showing examples of how Db2 Warehouse can continuously ingest millions of rows per second. And all of this, without sacrificing the ability to perform real time analytics with the lowest latency and continue to deliver the full range of analytics capabilities.
How does it perform?
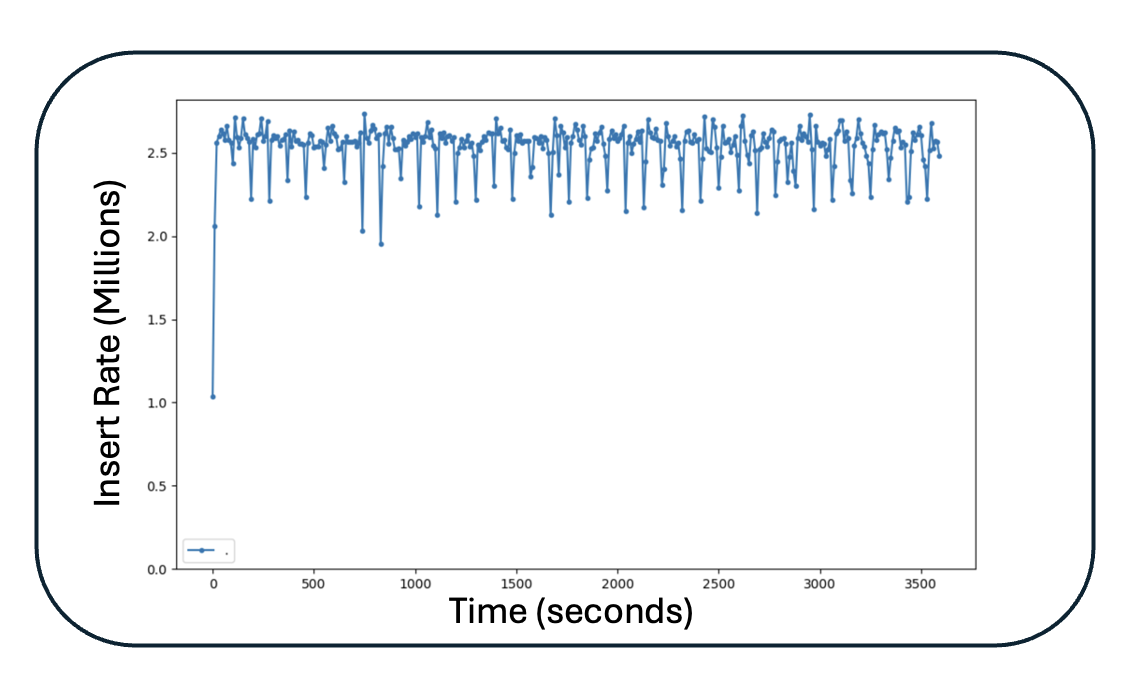
In order to answer the question, we’ve constructed a sample scenario that gives a sense of the volume and speed Db2 Warehouse on Cloud Gen3 can deliver when using Cloud Object Storage and the new multi-tier storage engine. In this example, we use a modern car as our sample IoT device, with around 100 sensors, each sensor producing 40-byte events every 5 seconds. This would generate in order of 2 million of events a day, and a total daily volume of approximately 65 MB of data. Now from there, it is easy to see that a float of 100,000 cars, a very small amount for any car manufacturer, would easily generate an average of over 2 million events per second, with a data volume that reaches 6.9 TB a day, 2.5 PB a year, and all of this must be ingested continuously to enable the real-time analytics use case. The chart below shows the ingestion performance into Db2 warehouse using this example. This test uses a set of 10 Java processes that are continuously ingesting these events in mini batches of 10,000 rows into 100 different tables within Db2 Warehouse on Cloud [See Endnote 1]. As you can see in the chart, this can easily reach 2.5 million events per second of continuous ingestion on two r5dn.24xlarge Amazon EC2 nodes, which would result in 3.15 Petabytes of data per year.
In the next sections of this blog, we do a technical deep dive into some of the features that we developed to enable these results, including:
- the new MEMORY_TABLE table function that enables the easy integration of a high-volume continuous ingestion process from any streaming software, like Apache Kafka or Apache Flink. In this example, this interface is being used for the continuous ingestion of the mini batches of 10,000 rows, with a total of 250 commits a second, which enable the real time querying of this data with sub-second latency.
- the new trickle-feed capabilities of column-organized tables that enables the efficient ingestion of data in mini batches, making it immediately available for querying, while the data is optimized in the background.
- the ability to store column-organized tables in Cloud Object Storage while preserving ingest performance, and with this be able to leverage the 34X cost savings when compared to legacy storage solutions. In this example, the cost of storing 3.5 PB a year is reduced from over several million USD per year with block storage to just over 100,000 USD per year with Cloud Object Storage! [See Endnote 2]
- and finally, the introduction of a multi-tier storage architecture, that enables Db2 Warehouse to deliver a 4X increase in query performance for both real-time and deep analytics.
Inserting batches of rows efficiently using MEMORY_TABLE and the Kafka Connector
Like we said, most of the real-time analytics use cases usually use streaming software, like Apache Kafka, Apache Flink or Spark Streaming, to simplify the data movement scenarios that need to handle large number of data sources continuously producing data that needs to be made available for analytics. These streaming applications all implement some sort of Sink Operator that is custom written for the target data repository.
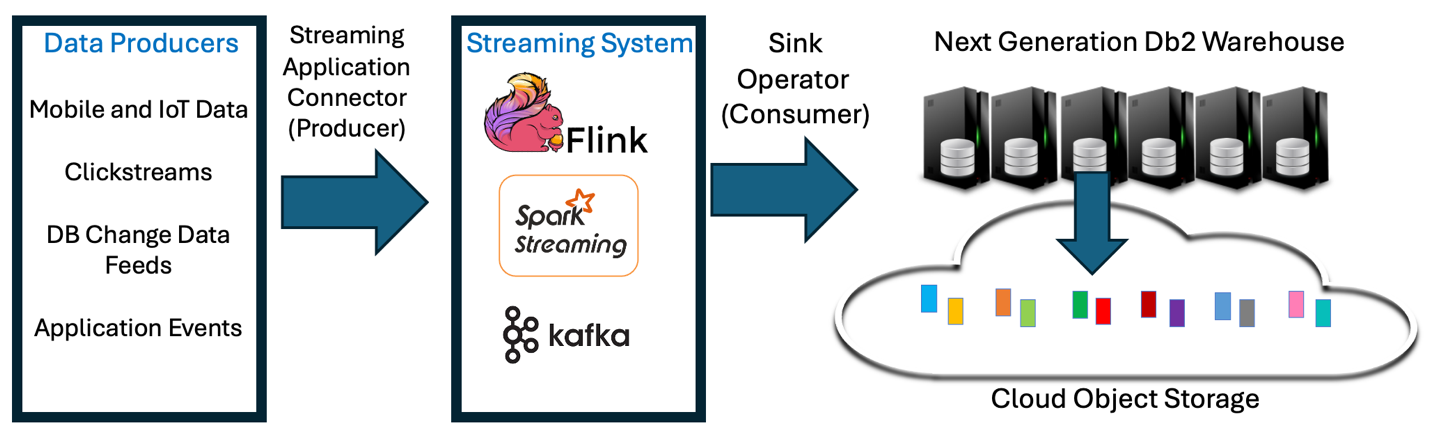
For this reason, Db2 Warehouse introduced the MEMORY_TABLE table function. Put simply, the MEMORY_TABLE table function allows any end user application, being that written in Java or any other language, to efficiently send batches of rows up to 2GB in size to a Db2 Warehouse database and ingest these batches through a simple INSERT-FROM-SUBSELECT transactional SQL request. Internally, when executed by the Db2 engine runtime, the MEMORY_TABLE table function generates the rows and feeds them into the ingestion process, which enhances the efficiency of the ingestion process. Once committed, the rows ingested become available for real-time analytics. The expectation is that the streaming software would maintain multiple database connections for parallel ingest streams and would be able to transactionally ingest batches of rows with sub-second latency through each of those streams. Here is a simple step-by-step guide to use the table function for a single ingest channel:
- Establish a connection to the database
- For each batch of rows
- Format a BLOB up to 2 GB in size with the rows that need to be ingested.
- Invoke an INSERT-FROM-SUBSELECT statement that includes the MEMORY_TABLE table function and commit the transaction to make the data available for real-time analytics.
INSERT INTO <table> SELECT * FROM TABLE(MEMORY_TABLE(<BLOB>));
COMMIT;
- Terminate the connection to the database
For an example of how this is exploited in an external application, we wrote a sample Kafka Connector for Db2 based on the JDBC connector that uses the new MEMORY_TABLE instead of doing individual insert operations for a batch of rows. You can find this sample connector in GitHub under https://github.com/ibmdb/kafka-connect-jdbc-sink-for-db2.
An important point is that to handle failures and retries, the client application could also, within the same transaction, update a bookmark with the last successful batched insert from the insert channel in a separate table, and all will be transactionally maintained by the database engine. This will allow the same insert channel to recover from failures and restart the ingest from the same point where it left off before the failure.
Trickle-feed inserts for Column-organized Tables
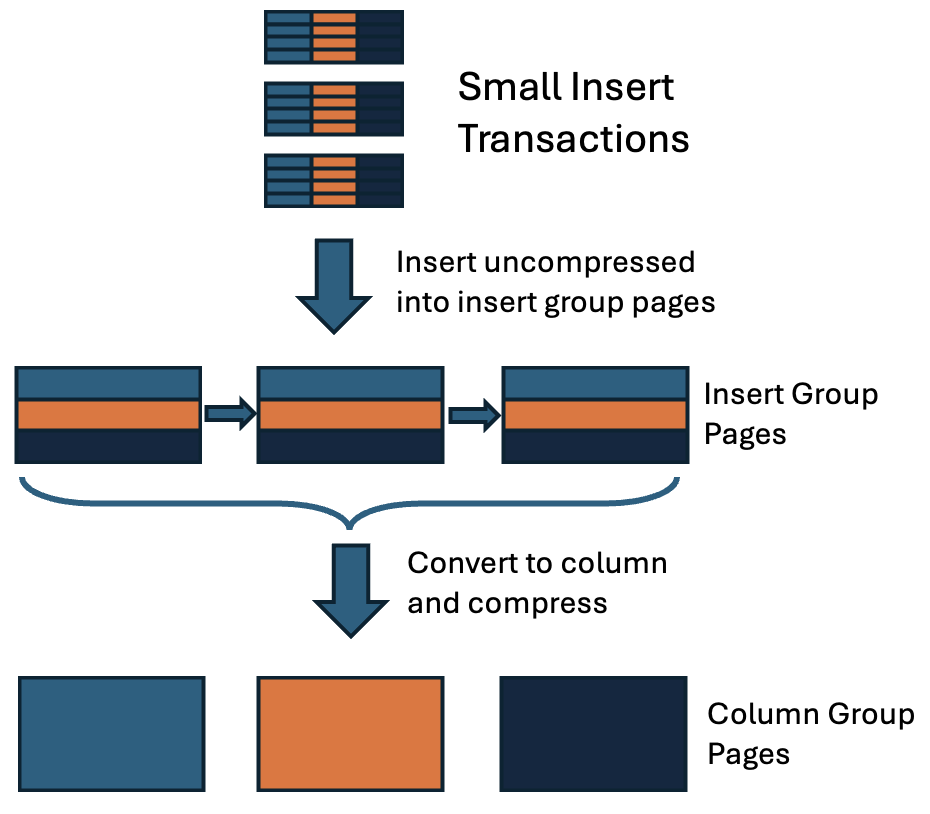
Trickle-feed inserts (i.e. inserts of a small number of rows over time) into a column-organized table in Db2 have always been much slower than inserts into comparable row-organized table, and for this, has been a pain point for continuous ingest scenarios and became a priority to be addressed. There are a few factors for this difference in performance, and all are directly proportional to the number of columns in the table being updated. The reason is that in column-organized tables, each external column belongs to its own Column Group (CG) and thus its data is ultimately stored on a separate data page, which results in many data pages updated vs a single page updated for row-organized tables. In addition, each page update requires a separate log record within the Db2 transaction log in order to ensure recoverability, and also in column-organized tables, compression is applied immediately and individually, which makes the incremental page updates more costly. In order to accelerate trickle-feed insert performance, Db2 has made some changes in the 11.5 release stream that improve the efficiency through avoiding initially separating small inserts into different pages for each column until there is enough volume to justify this organization. For this, multiple CGs are combined in so-called Insert (Column) Groups for the initial insert processing at small volumes, which constitutes an alternate way of defining the relationship of CGs to data pages. With this, all CGs associated with an Insert Group are stored on the same data page. The system internally determines a mapping of CGs to Insert Groups that minimizes partial pages and the corresponding impact to insert performance. Subsequently, to optimize query performance, the data in Insert Group format is split and saved in separate CG pages, so that most data is stored in columnar format. When a relatively small number of Insert Group pages have been filled, the insert statement that just filled the last Insert Group page performs an efficient splitting of all existing Insert Group data pages into the separate CG data, compresses the rows within the new pages independently based on the corresponding dictionaries, and stores the compressed data in the standard CG format on separate pages. The following diagram shows this 2-step ingestion process:
Integrating trickle-feed inserts into
the LSM Tree Storage Layer without losing Performance
As described above, the optimizations developed for trickle-feed inserts into column organized tables reduce the number of page writes and consequently synchronously logged to the Db2 transaction log, which significantly improved the performance of these transactions with a relatively small number of rows. However, there were still challenges to make this perform when using Cloud Object Storage, which was required in order to enable cost-efficient storage of very large data volumes. The challenges with the writes to new LSM tree storage layer for Cloud Object Storage were in two areas: 1) the writes incur an additional logging step for the page update into the LSM storage layer WAL (Write-Ahead-Log) in order to guarantee persistence, and 2) the writes require a synchronous wait for the asynchronous write to Cloud Object Storage before the disk space used by the LSM storage layer WAL that contains the corresponding log entries could be freed.
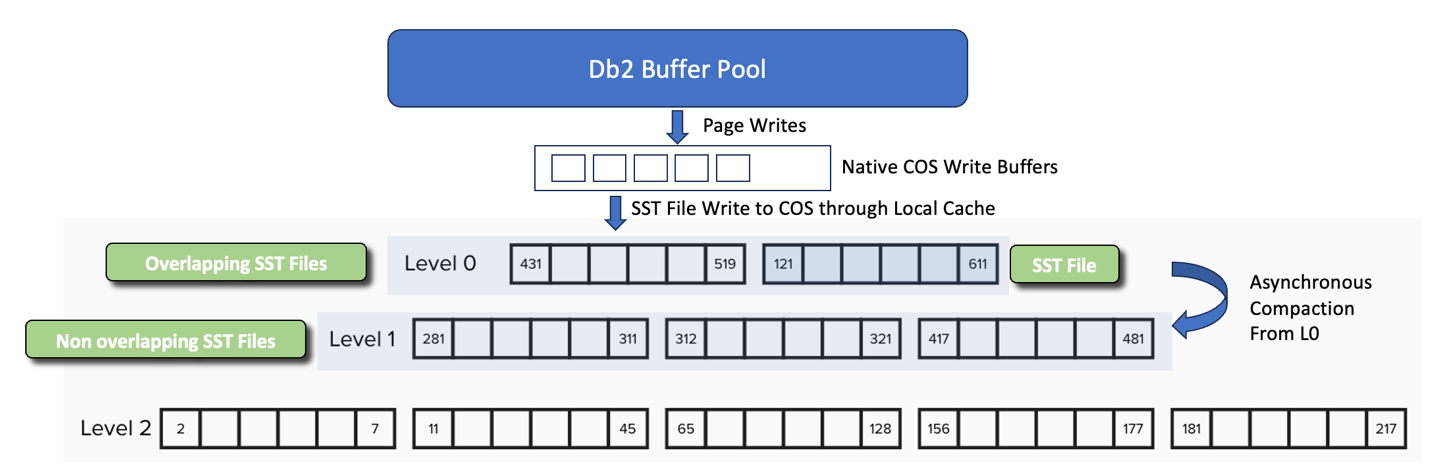
Before moving on to the newly developed optimization to overcome those challenges, let’s look at the ingest process through this new storage layer in order to understand the full context. The following diagram exemplifies this process, showing pages being written directly into in-memory LSM tree storage layer Write Buffers from the Db2 Buffer Pool, and subsequently written to COS in the form of an SST file, and positioning them at the top of the LSM tree (Level 0). Since this level within the LSM tree allows for key range overlaps between SST files, there is no synchronous performance impact during ingest to enforce ordering. Then as the diagram shows, once there is sufficient volume of SST files in Level 0, the background asynchronous process merges some of these into subsequent levels that are non-overlapping key ranges and makes these more efficient to query.
The important point about this is that in order to ensure durability, the LSM storage layer manages its own Write-Ahead-Log, for which this insert process resulted in double synchronous logging (Db2 write ahead log + LSM storage layer WAL) to the same low latency persistent storage. This also required additional logging space for insert operations that in some cases can amount to a significant portion of data ingest processing. For this reason, we developed an additional optimization in order to improve the ingest performance by avoiding the double logging by leveraging two design elements:
- First, the existing oldest dirty page tracking in Db2 (minBuffLSN), that identifies the log sequence number (LSN) of the oldest page that has not been flushed to disk from the Db2 buffer pool and that requires Db2 to hold its corresponding Db2 transaction log records to ensure recoverability. This tracking is used by the proactive page cleaning to limit the number of non-persisted pages in the Db2 buffer pool. As you probably know, this mechanism is controlled by the user configured time for the oldest dirty page within the buffer pool (known as “Page Age Target") which in turn bounds the maximum recovery time.
- Second, the LSM storage layer asynchronous “write tracked writes” which support the ability to write batches of data pages asynchronously through the LSM storage layer Write Buffers, tag each write with a monotonically increasing sequence number, and with this be able to easily identify the writes that are still in a Write Buffer and not yet flushed to Cloud Object Storage.
In order to integrate a) and b), the Db2 Buffer Pool provides the LSM storage layer with the corresponding page LSN as the monotonically increasing write tracking sequence number for each page, which enables it to identify the completion of the persistence for the asynchronous write operation of those pages. When Db2 computes the minBuffLSN to make the decision to free up a portion of the Db2 transaction log stream, it now computes it from a combination of the minimum write tracking sequence number that has not been persisted yet to Cloud Object Storage by the LSM storage layer, together with Db2’s minBuffLSN in order to compute the true minBuffLSN. With this, Db2’s transaction log is preserved until the writes to the LSM storage layer have been fully persisted to cloud object storage and removed the need to also log these writes to the LSM layer WAL, removing the double logging.
Conclusion
As we said when in the introduction, Db2 Warehouse has always delivered the ability to perform the full spectrum of analytics, from deep analytics to real time analytics. In recent years, the challenges on the real time space have grown, with data volumes growing larger, with an expectation that they are continuously ingested in Data Warehouses instead of being batch ingested, and with the need to perform real time analytics much closer to the time when the data is generated, as close as within seconds. All of these are the motivations for the innovations discussed in this blog post. Like you saw, the innovations in the interfaces and columnar runtime engine lead to a much more efficient continuous ingestion process that can be truly integrated into data streaming pipelines. And the innovations in the storage architecture to introduce Cloud Object Storage for storage of native Db2 column-organized tables opens the door to cost-efficiently maintaining Petabytes of data in your Data Warehouse.
About the Authors
Christian Garcia-Arellano is Senior Technical Staff Member, Master Inventor and lead architect in the DB2 Kernel Development team at the IBM Toronto Lab and has a MSc in Computer Science from the University of Toronto. Christian has been working in various DB2 Kernel development areas since 2001. Initially Christian worked on the development of the self-tuning memory manager (STMM) and led various of the high availability features for DB2 pureScale that make it the industry leading database in availability. More recently, Christian was one of the architects for Db2 Event Store, and the leading architect of the Native Cloud Object Storage feature in Db2 Warehouse. Christian can be reached at cmgarcia@ca.ibm.com.
Daniel Zilio has a PhD in Computer Science and has been with IBM for 25 years. Daniel has been one of the fathers of physical database design methods within IBM, including developing methods to automatically select indexes, DPF distribution keys, as well as MQTs. He was also a senior member of the Db2 compiler team and has recently worked on introducing column organized MQTs on Native COS. Daniel can be reached at zilio@ca.ibm.com.
Kostas Rakopoulos is a member of the Db2 Performance team at the IBM Toronto Lab and has a BSc in Computer Science from the University of Toronto. Since joining the Db2 Performance team in 2008, Kostas has worked on a wide range of Db2 offering types including Db2 pureScale (OLTP), Db2 Event Store (IoT) and Db2 Warehouse. Most recently, Kostas has been working on the Native Cloud Object Storage feature in Db2 Warehouse. Kostas can be reached at kostasr@ca.ibm.com.
Endnotes
[1] The Db2 Warehouse on Cloud Gen3 environment used for the test includes two r5dn.24xlarge Amazon EC2 nodes running with 12 database partitions per node. Each node consists of 96 vCPUs, 768 GiB memory, 12 EBS io2 volumes (6 IOPS/GB), 4 locally attached NVMe drives (900 GB each) and a 100 Gbps network. For COS we use Amazon S3 Standard class in the same region as the EC2 nodes to minimize the latency.
[2] Block Storage vs Cloud Object Storage comparison depicts difference between published prices for Amazon EBS 1TB io2 volumes at 6 IOPS/GB (and additional tiers to support Db2 data) vs Amazon S3. This metric is not an indicator of future storage pricing for Db2 Warehouse Gen 3.