Simplify Query Performance Tuning with the Db2 AI Query Optimizer
The previous AI Query Optimizer blogs covered the motivations and features behind the AI Query Optimizer as well as the neural networks that power it.
In this installment, we will discuss how to use the AI Query Optimizer by working through an example. The example will showcase the power of the AI Query Optimizer and how it works together with the traditional query optimizer to improve query performance. Follow along with your own Db2 12.1 instance; no other tools required!
We will also explore some methods to help manage the automatic creation and usage of models, and look at ways to gather more details about them. So let’s get started!
The database setup
The example we will go through uses the tables from the db2sampl command in a non-partitioned database environment. Feel free to follow along with a partitioned database environment as well, just keep in mind the commands and statements we will be using throughout the example may return different results.
The default database name is SAMPLE and that is the database name we will use in this example. If you wish to create the sample database with a different name, you can specify the -name <database-name> parameter and provide your desired database name. db2sampl uses the CURRENT SCHEMA special register as the schema qualifying the database objects. In this example, we will use SAMPLE as the schema.
Once db2sampl has completed, the sample tables are populated and ready to use after connecting to the database.
Before we continue, we should also ensure the AI Query Optimizer is enabled for the database.
How do I enable the AI Query Optimizer?
Starting in Db2 12.1, the AI Query Optimizer introduces a new hierarchy of database configuration parameters under the “Automatic maintenance (AUTO_MAINT)” hierarchy called “Automatic AI maintenance”. To enable the AI Query Optimizer (or AI Optimizer for short), we must switch the “AI Optimizer (AUTO_AI_OPTIMIZER)” database configuration parameter to ON.
For new databases, such as the SAMPLE database we created above, the default configuration of the database parameters in this new hierarchy is as follows:
Automatic AI maintenance (AUTO_AI_MAINT) = ON
AI Optimizer (AUTO_AI_OPTIMIZER) = ON
Automatic Model Discovery (AUTO_MODEL_DISCOVER) = ON
As we can see, the AI Optimizer is enabled automatically for newly created databases. Therefore, no configuration changes are needed to start using the AI Optimizer for the SAMPLE database. For now let’s not worry about the other two database configuration parameters AUTO_AI_MAINT and AUTO_MODEL_DISCOVER, we will discuss those later.
TIP
For existing databases that have been upgraded to Db2 12.1, the default configuration of these database parameters is as follows:
Automatic AI maintenance (AUTO_AI_MAINT) = ON
AI Optimizer (AUTO_AI_OPTIMIZER) = OFF
Automatic Model Discovery (AUTO_MODEL_DISCOVER) = ON
To enable the AI Optimizer for upgraded databases, the “AI Optimizer (AUTO_AI_OPTIMIZER)” configuration parameter must be turned on (where <DATABASE-NAME> is the name of the upgraded database):
UPDATE DATABASE CONFIGURATION FOR <DATABASE-NAME> USING AUTO_AI_OPTIMIZER ON;
The AUTO_AI_OPTIMIZER database configuration parameter has a propagation class of immediate and is therefore updated immediately. The IMMEDIATE keyword for the UPDATE DATABASE CONFIGURATION command is not required as it is the default action. The same also applies to the new AUTO_AI_MAINT and AUTO_MODEL_DISCOVER database configuration parameters.
Once we’ve ensured AUTO_AI_OPTIMIZER is switched on, we are ready to continue! With the AI Optimizer enabled, cardinality estimation models are created automatically by the automatic statistics collection facility and used automatically when applicable during query optimization; no user input required!
As we work through these examples, we will also cover how to monitor and influence usage of the AI Optimizer’s cardinality estimation models if that level of control is needed in your environment.
Cardinality Estimation with the Traditional Optimizer
To fully appreciate the benefits of the AI Optimizer, let’s see how the optimizer computes cardinality estimations for a query using traditional algorithms with statistics to evaluate how accurate they are. Once we explain the query with section actuals and take a look at how well the traditional optimizer algorithms estimate cardinalities, we will explain the query again with the AI Optimizer and see how it compares.
Before we continue, it’s important to keep in mind that although the SAMPLE database is great for quickly setting up a test environment to evaluate, the tables contain very little data. This means while we will be able to compare query access plans, a better access plan will likely have very little effect on the execution time of the query. The query execution time benefits of improved access plans become more apparent at scale, so to meaningfully compare the execution performance of the different access plans yourself, you will need to scale up the SAMPLE table data.
Let’s start by collecting some statistics that the traditional optimizer will use to assist with computing cardinality estimations. We will execute the RUNSTATS command on all the tables referenced in our query using the same default options that are used by the automatic statistics collection facility like so:
RUNSTATS ON TABLE SAMPLE.EMPLOYEE WITH DISTRIBUTION AND DETAILED INDEXES ALL;
RUNSTATS ON TABLE SAMPLE.PROJECT WITH DISTRIBUTION AND DETAILED INDEXES ALL;
RUNSTATS ON TABLE SAMPLE.DEPARTMENT WITH DISTRIBUTION AND DETAILED INDEXES ALL;
RUNSTATS ON TABLE SAMPLE.EMP_ACT WITH DISTRIBUTION AND DETAILED INDEXES ALL;
RUNSTATS ON TABLE SAMPLE.PROJACT WITH DISTRIBUTION AND DETAILED INDEXES ALL;
Now that we have statistics on each table, let’s go ahead and take a look at the main query we will be diving into:
SELECT
EMPLOYEE.FIRSTNME,
EMPLOYEE.LASTNAME,
EMPLOYEE.WORKDEPT,
DEPARTMENT.ADMRDEPT,
DEPARTMENT.DEPTNAME,
PROJECT.PROJNO,
PROJECT.PROJNAME,
EMP_ACT.ACTNO,
EMP_ACT.EMPTIME,
PROJACT.ACSTAFF
FROM
SAMPLE.EMPLOYEE EMPLOYEE,
SAMPLE.DEPARTMENT DEPARTMENT,
SAMPLE.PROJECT PROJECT,
SAMPLE.EMP_ACT EMP_ACT,
SAMPLE.PROJACT PROJACT
WHERE
DEPARTMENT.DEPTNO = EMPLOYEE.WORKDEPT AND
EMPLOYEE.WORKDEPT = PROJECT.DEPTNO AND
EMPLOYEE.EMPNO = EMP_ACT.EMPNO AND
PROJECT.PROJNO = PROJACT.PROJNO AND
PROJECT.PRENDATE BETWEEN '12/31/2001' AND '12/31/2003' AND
PROJECT.PRSTAFF < 13 AND
PROJECT.RESPEMP > '000019' AND
PROJECT.MAJPROJ LIKE 'AD3%' AND
EMPLOYEE.WORKDEPT LIKE 'D%' AND
EMPLOYEE.JOB IN ('CLERK', 'FIELDREP', 'DESIGNER', 'MANAGER', 'OPERATOR') AND
EMPLOYEE.HIREDATE BETWEEN '01/01/1995' AND '12/31/2004' AND
EMPLOYEE.BIRTHDATE > '01/01/1960' AND
EMPLOYEE.BIRTHDATE <= '12/31/2002' AND
EMPLOYEE.EMPNO LIKE '000%' AND
EMPLOYEE.EDLEVEL >= 14 AND
EMPLOYEE.SALARY BETWEEN 45000 AND 58000 AND
EMPLOYEE.BONUS <= DECIMAL(600) AND
EMPLOYEE.COMM <= DECIMAL(2350.0) AND
EMPLOYEE.COMM >= DECIMAL(1400.0) AND
EMPLOYEE.SEX = 'M'
ORDER BY
EMPLOYEE.FIRSTNME,
EMPLOYEE.LASTNAME;
Query 1, contains a five table join between the EMPLOYEE, DEPARTMENT, PROJECT, EMP_ACT, and PROJACT sample tables. There are four join predicates that join the five tables together along with a mix of different local predicates on the EMPLOYEE and PROJECT tables.
Executing this query, we see that it returns 319 rows:

What we will do shortly is collect the access plan with section actuals for this query using the traditional optimizer so we can see how well it estimates the table cardinalities after applying local predicates. To help us evaluate the estimates, let’s collect the actual number of rows returned by a couple of tables in the query (EMPLOYEE and PROJECT) after applying their respective local predicates from query 1. We will also be able to see the actual number of rows flowing through each optimizer operator with section actuals.
Let’s run the following COUNT(*) queries:
SELECT
COUNT(*)
FROM
SAMPLE.EMPLOYEE EMPLOYEE
WHERE
EMPLOYEE.WORKDEPT LIKE 'D%' AND
EMPLOYEE.JOB IN ('CLERK', 'FIELDREP', 'DESIGNER', 'MANAGER', 'OPERATOR') AND
EMPLOYEE.HIREDATE BETWEEN '01/01/1995' AND '12/31/2004' AND
EMPLOYEE.BIRTHDATE > '01/01/1960' AND
EMPLOYEE.BIRTHDATE <= '12/31/2002' AND
EMPLOYEE.EMPNO LIKE '000%' AND
EMPLOYEE.EDLEVEL >= 14 AND
EMPLOYEE.SALARY BETWEEN 45000 AND 58000 AND
EMPLOYEE.BONUS <= DECIMAL(600) AND
EMPLOYEE.COMM <= DECIMAL(2350.0) AND
EMPLOYEE.COMM >= DECIMAL(1400.0) AND
EMPLOYEE.SEX = 'M';
SELECT
COUNT(*)
FROM
SAMPLE.PROJECT PROJECT
WHERE
PROJECT.PRENDATE BETWEEN '12/31/2001' AND '12/31/2003' AND
PROJECT.PRSTAFF < 13 AND
PROJECT.RESPEMP > '000019' AND
PROJECT.MAJPROJ LIKE 'AD3%';
Here are the results:
|
Query |
Table |
Rows |
|
2 |
EMPLOYEE |
5 |
|
3 |
PROJECT |
4 |
Now that we know the actual number of rows flowing out from these tables, let’s collect the access plan of query 1 with section actuals. We can do so by using the db2caem tool as follows:
db2caem -d SAMPLE -sf query1.sql
The file query1.sql contains query 1 modified slightly with an optimizer guideline:
SELECT
EMPLOYEE.FIRSTNME,
EMPLOYEE.LASTNAME,
EMPLOYEE.WORKDEPT,
DEPARTMENT.ADMRDEPT,
DEPARTMENT.DEPTNAME,
PROJECT.PROJNO,
PROJECT.PROJNAME,
EMP_ACT.ACTNO,
EMP_ACT.EMPTIME,
PROJACT.ACSTAFF
FROM
SAMPLE.EMPLOYEE EMPLOYEE,
SAMPLE.DEPARTMENT DEPARTMENT,
SAMPLE.PROJECT PROJECT,
SAMPLE.EMP_ACT EMP_ACT,
SAMPLE.PROJACT PROJACT
WHERE
DEPARTMENT.DEPTNO = EMPLOYEE.WORKDEPT AND
EMPLOYEE.WORKDEPT = PROJECT.DEPTNO AND
EMPLOYEE.EMPNO = EMP_ACT.EMPNO AND
PROJECT.PROJNO = PROJACT.PROJNO AND
PROJECT.PRENDATE BETWEEN '12/31/2001' AND '12/31/2003' AND
PROJECT.PRSTAFF < 13 AND
PROJECT.RESPEMP > '000019' AND
PROJECT.MAJPROJ LIKE 'AD3%' AND
EMPLOYEE.WORKDEPT LIKE 'D%' AND
EMPLOYEE.JOB IN ('CLERK', 'FIELDREP', 'DESIGNER', 'MANAGER', 'OPERATOR') AND
EMPLOYEE.HIREDATE BETWEEN '01/01/1995' AND '12/31/2004' AND
EMPLOYEE.BIRTHDATE > '01/01/1960' AND
EMPLOYEE.BIRTHDATE <= '12/31/2002' AND
EMPLOYEE.EMPNO LIKE '000%' AND
EMPLOYEE.EDLEVEL >= 14 AND
EMPLOYEE.SALARY BETWEEN 45000 AND 58000 AND
EMPLOYEE.BONUS <= DECIMAL(600) AND
EMPLOYEE.COMM <= DECIMAL(2350.0) AND
EMPLOYEE.COMM >= DECIMAL(1400.0) AND
EMPLOYEE.SEX = 'M'
ORDER BY
EMPLOYEE.FIRSTNME,
EMPLOYEE.LASTNAME
/*<OPTGUIDELINES>
<REGISTRY>
<OPTION NAME='DB2_SELECTIVITY' VALUE='MODEL_PRED_SEL OFF'/>
</REGISTRY>
</OPTGUIDELINES>*/;
This optimizer guideline sets a new DB2_SELECTIVITY registry variable value named MODEL_PRED_SEL to OFF. This guideline will ensure any AI Optimizer models that may have been automatically created by this point on the tables inside the query will be ignored during query optimization. Doing so causes the query to be optimized using the traditional optimizer algorithms and not have its cardinality estimates influenced by any AI Optimizer models. We will remove this guideline later to see how the AI Optimizer-assisted access plan compares.
Let’s take a look at the “Access Plan” section in the generated db2caem.exfmt.1 file:
Access Plan:
-----------
Total Cost: 61.4988
Query Degree: 1
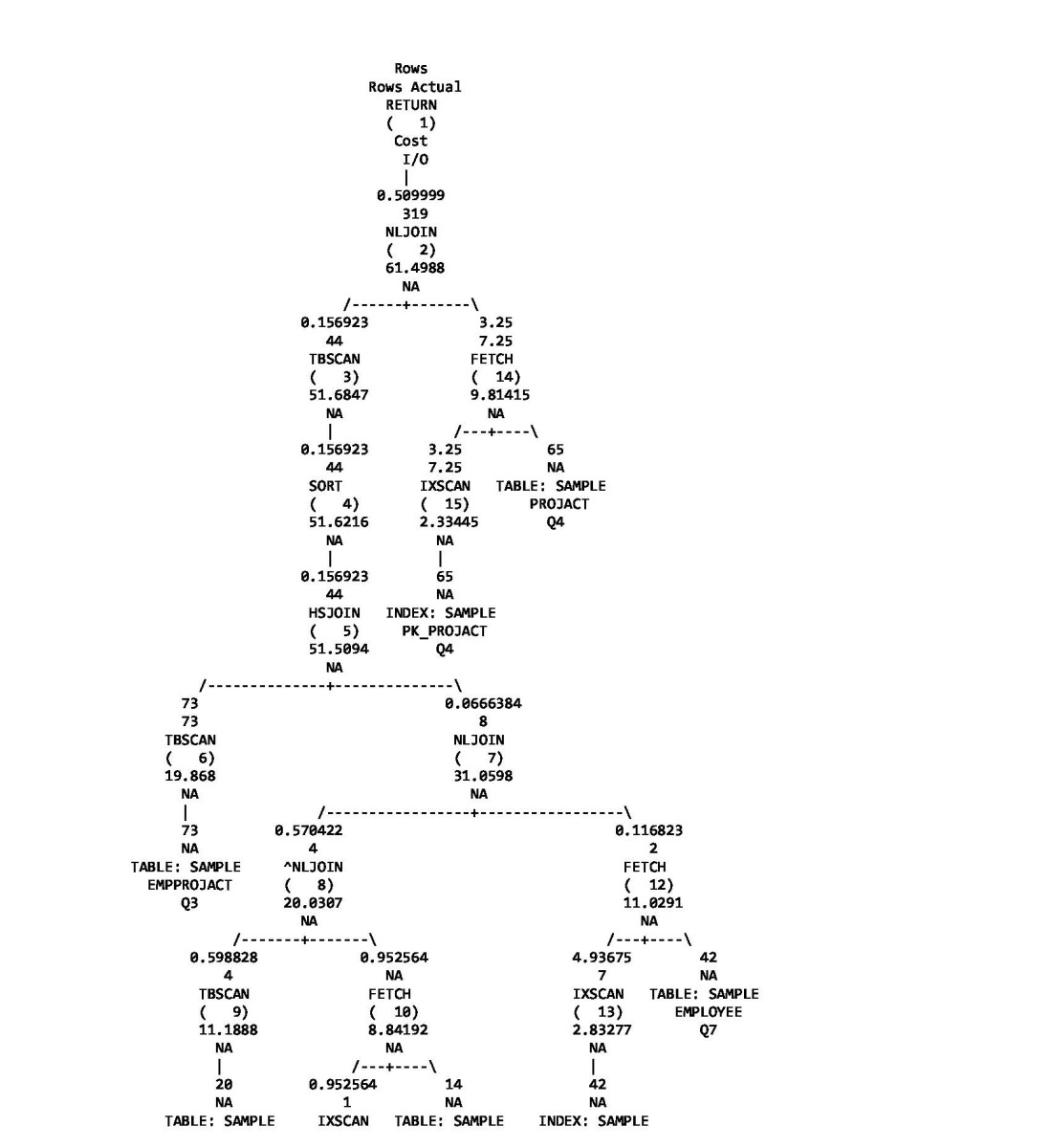
Focusing on the two tables in the access plan with local predicates, EMPLOYEE and PROJECT, we can see the traditional optimizer under-estimates the cardinalities. For the EMPLOYEE table, the IXSCAN operator estimates 4.94 rows and the FETCH operator estimates 0.12 rows after applying both local and join predicates while the actual number of rows from those operators are 7 and 2 respectively. As we saw from query 2, the actual number of rows after applying local predicates is 5, but we do not see the local predicate estimation and actuals in the access plan since there are join predicates applied on the IXSCAN and both the IXSCAN and FETCH estimates are per-outer values. For the PROJECT table, the TBSCAN operator estimates 0.6 rows after applying local predicates while the actual number of rows is 4. These errors in the estimates propagate to the NLJOIN estimating 0.0666 rows and the resulting final cardinality estimation is 0.51 rows which is about three orders of magnitude away from the actual cardinality of 319 rows.
Creating AI Optimizer models
Now that we’ve seen what the access plan looks like for query 1 with the traditional optimizer, we can use the AI Optimizer to help us improve the access plan. The AI Optimizer will have automatically created cardinality estimation models for us on the EMPLOYEE and PROJECT tables which will be used automatically by the query optimizer to create a new access plan. The cardinality estimation models will assist with estimating the cardinalities of multiple local equality, range/between, LIKE with trailing or no wildcard in the string pattern, IN, and OR predicates.
Since the AI Optimizer models are discovered and trained automatically through automatic statistics collection, we may need to wait a bit for the models we care about on EMPLOYEE and PROJECT to be created. Model discovery and training for both tables could start within five minutes if real-time statistics schedules an asynchronous statistics collection request. Otherwise, model discovery and training should start within two hours using automatic background statistics collection.
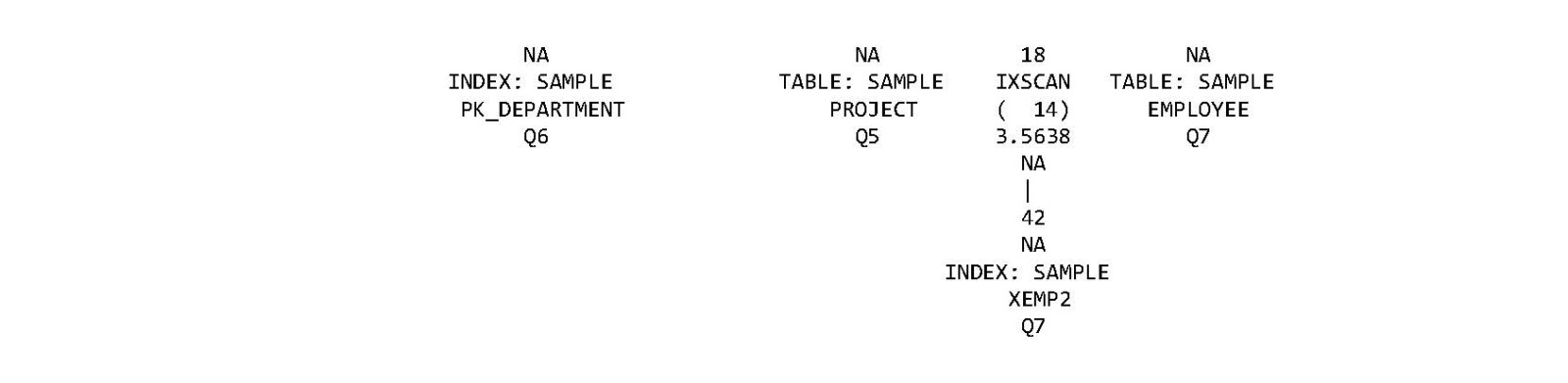
We can periodically confirm the models exist by running a query on a new catalog view called SYSCAT.AIOPT_TABLECARDMODELS. This catalog view contains information about the AI Optimizer models available within the database along with the tables they are associated with.
Let’s run the following query:
SELECT
VARCHAR(MODELSCHEMA, 25) AS MODELSCHEMA,
VARCHAR(MODELNAME, 25) AS MODELNAME,
VARCHAR(TABSCHEMA, 25) AS TABSCHEMA,
VARCHAR(TABNAME, 25) AS TABNAME,
VARCHAR(TABCOLUMNS, 100) AS TABCOLUMNS
FROM
SYSCAT.AIOPT_TABLECARDMODELS
WHERE
TABSCHEMA = 'SAMPLE' AND
TABNAME IN ('EMPLOYEE', 'PROJECT');
When models for both tables are created, we should see results similar to the following:
 We can see there is a model available for both tables. The MODELSCHEMA and MODELNAME columns identify the name of the model object (the model name is automatically generated), and the TABSCHEMA, TABNAME, and TABCOLUMNS identify the table and the columns the model was created for. There are other useful columns we can query from this catalog view which we will look at later.
We can see there is a model available for both tables. The MODELSCHEMA and MODELNAME columns identify the name of the model object (the model name is automatically generated), and the TABSCHEMA, TABNAME, and TABCOLUMNS identify the table and the columns the model was created for. There are other useful columns we can query from this catalog view which we will look at later.
We can also take a look in the optimizer statistics log (OPTSTATS log) which contains event logs about model discovery and training that occurred during automatic statistics collection. For example, let’s look for DISCOVER and TRAIN log entries for the EMPLOYEE table in the OPTSTATS log (located in the events folder of the instance’s DIAGPATH, or queryable using the SYSPROC.PD_GET_DIAG_HIST table function by specifying the ‘OPTSTATS’ facility):
2024-11-10-23.32.59.201144-300 I1260412E762 LEVEL: Event
PID : 171207 TID : 140253327255104 PROC : db2sysc
INSTANCE: sample NODE : 000 DB : SAMPLE4
APPHDL : 0-164 APPID: *LOCAL.sample.241111043423
UOWID : 2 LAST_ACTID: 0
AUTHID : SAMPLE HOSTNAME: sample-xex6b-x86
EDUID : 147 EDUNAME: db2agent (SAMPLE4)
FUNCTION: DB2 UDB, relation data serv, sqlrLocalRunstats, probe:11653
DISCOVER: TABLE CARDINALITY MODEL : Object name with schema : AT "2024-11-10-23.32.59.201077" : BY "Asynchronous" :
start
OBJECT : Object name with schema, 17 bytes
SAMPLE.EMPLOYEE
IMPACT : None
DATA #1 : String, 18 bytes
Automatic Runstats
2024-11-10-23.32.59.203724-300 I1261175E965 LEVEL: Event
PID : 171207 TID : 140253327255104 PROC : db2sysc
INSTANCE: sample NODE : 000 DB : SAMPLE4
APPHDL : 0-164 APPID: *LOCAL.sample.241111043423
UOWID : 2 LAST_ACTID: 0
AUTHID : SAMPLE HOSTNAME: sample-xex6b-x86
EDUID : 147 EDUNAME: db2agent (SAMPLE4)
FUNCTION: DB2 UDB, relation data serv, sqlrLocalRunstats, probe:12096
DISCOVER: TABLE CARDINALITY MODEL : Object name with schema : AT "2024-11-10-23.32.59.203679" : BY "Asynchronous" :
success
OBJECT : Object name with schema, 17 bytes
SAMPLE.EMPLOYEE
IMPACT : None
DATA #1 : String, 18 bytes
Automatic Runstats
DATA #2 : String, 172 bytes
TABLE CARDINALITY MODEL ON "SAMPLE"."EMPLOYEE" ON COLUMNS ("EMPNO", "FIRSTNME", "MIDINIT", "LASTNAME", "WORKDEPT",
"PHONENO", "JOB", "EDLEVEL", "SALARY", "BONUS", "COMM")
2024-11-10-23.32.59.207182-300 I1262902E976 LEVEL: Event
PID : 171207 TID : 140253327255104 PROC : db2sysc
INSTANCE: sample NODE : 000 DB : SAMPLE4
APPHDL : 0-164 APPID: *LOCAL.sample.241111043423
UOWID : 2 LAST_ACTID: 0
AUTHID : SAMPLE HOSTNAME: sample-xex6b-x86
EDUID : 147 EDUNAME: db2agent (SAMPLE4)
FUNCTION: DB2 UDB, relation data serv, SqlrSqmlCardEstModel::trainModel, probe:100
TRAIN : TABLE CARDINALITY MODEL : Object name with schema : AT "2024-11-10-23.32.59.207132" : BY "Asynchronous" :
start
OBJECT : Object name with schema, 17 bytes
SAMPLE.EMPLOYEE
IMPACT : None
DATA #1 : String, 18 bytes
Automatic Runstats
DATA #2 : String, 172 bytes
TABLE CARDINALITY MODEL ON "SAMPLE"."EMPLOYEE" ON COLUMNS ("EMPNO", "FIRSTNME", "MIDINIT", "LASTNAME", "WORKDEPT",
"PHONENO", "JOB", "EDLEVEL", "SALARY", "BONUS", "COMM")
2024-11-10-23.33.38.216545-300 I1263879E2225 LEVEL: Event
PID : 171207 TID : 140253327255104 PROC : db2sysc
INSTANCE: sample NODE : 000 DB : SAMPLE4
APPHDL : 0-164 APPID: *LOCAL.sample.241111043423
UOWID : 2 LAST_ACTID: 0
AUTHID : SAMPLE HOSTNAME: sample-xex6b-x86
EDUID : 147 EDUNAME: db2agent (SAMPLE4)
FUNCTION: DB2 UDB, relation data serv, SqlrSqmlCardEstModel::trainModel, probe:200
TRAIN : TABLE CARDINALITY MODEL : Object name with schema : AT "2024-11-10-23.33.38.216464" : BY "Asynchronous" :
success
OBJECT : Object name with schema, 17 bytes
SAMPLE.EMPLOYEE
IMPACT : None
DATA #1 : String, 18 bytes
Automatic Runstats
DATA #2 : String, 1418 bytes
Model metrics: Rating: 2 (Good), Table samples: 42 (42), Flags: 0x0, Training time: 39009 (1/604/101/1), Low Bound Threshold: 0.025000, Validation MSE: 0.000540, Accuracy bucket counts: 348,13731,36773,15933,1134, Accuracy bucket means: -2.279368,-1.307043,-0.155885,1.290627,2.504066
Table column cardinalities: 42,39,21,41,8,32,8,8,40,8,32
Sample column cardinalities: 42,39,21,41,8,32,8,8,40,8,32
Sample column mappings: 42,39,21,41,8,32,8,8,40,8,32
Column flags: 00000103,00000101,00000101,00000101,00000021,00000101,00000001,00000001,00000101,00001401,00001501
Base algorithm metrics: Training metric: 0.000000, Validation metric: 0.000547, Previous validation metric: 0.000553, Pre-training validation metric: 0.002436, Used training iterations: 15, Configured training iterations: 15, Training set size: 679181, Pre-training time: 1031, Training time: 21533, Accuracy bucket counts: 240,13261,32137,20860,1421, Accuracy bucket means: -2.256163,-1.285914,0.039890,1.315500,2.488634
Low selectivity algorithm metrics: Training metric: 0.000000, Validation metric: 0.000401, Previous validation metric: 0.057680, Pre-training validation metric: 0.113618, Used training iterations: 24, Configured training iterations: 24, Training set size: 273432, Pre-training time: 1018, Training time: 16770, Accuracy bucket counts: 737,8706,2204,13599,839, Accuracy bucket means: -2.312980,-1.436001,-0.096435,1.240184,2.472025
The DISCOVER and TRAIN logs come in start/success pairs that detail the exact time model discovery and training was started and finished. These logs also show us similar information as the query on the SYSCAT.AIOPT_TABLECARDMODELS catalog view. We can see the EMPLOYEE table has a subset of its columns discovered and used for a successful model training.
Similar to SYSCAT.AIOPT_TABLECARDMODELS, if we see DISCOVER and TRAIN OPTSTATS log entries for both the EMPLOYEE and PROJECT tables, we know they are ready to be used for cardinality estimation.
Cardinality Estimation with AI Optimizer Models
Now that we know we have models on the EMPLOYEE and PROJECT tables, let’s collect the access plan and section actuals of query 1 without the optimizer guideline to allow the AI Optimizer to assist the query optimizer with cardinality estimation:
db2caem -d SAMPLE -sf query1.sql
The file query1.sql contains query 1 without the optimizer guideline:
SELECT
EMPLOYEE.FIRSTNME,
EMPLOYEE.LASTNAME,
EMPLOYEE.WORKDEPT,
DEPARTMENT.ADMRDEPT,
DEPARTMENT.DEPTNAME,
PROJECT.PROJNO,
PROJECT.PROJNAME,
EMP_ACT.ACTNO,
EMP_ACT.EMPTIME,
PROJACT.ACSTAFF
FROM
SAMPLE.EMPLOYEE EMPLOYEE,
SAMPLE.DEPARTMENT DEPARTMENT,
SAMPLE.PROJECT PROJECT,
SAMPLE.EMP_ACT EMP_ACT,
SAMPLE.PROJACT PROJACT
WHERE
DEPARTMENT.DEPTNO = EMPLOYEE.WORKDEPT AND
EMPLOYEE.WORKDEPT = PROJECT.DEPTNO AND
EMPLOYEE.EMPNO = EMP_ACT.EMPNO AND
PROJECT.PROJNO = PROJACT.PROJNO AND
PROJECT.PRENDATE BETWEEN '12/31/2001' AND '12/31/2003' AND
PROJECT.PRSTAFF < 13 AND
PROJECT.RESPEMP > '000019' AND
PROJECT.MAJPROJ LIKE 'AD3%' AND
EMPLOYEE.WORKDEPT LIKE 'D%' AND
EMPLOYEE.JOB IN ('CLERK', 'FIELDREP', 'DESIGNER', 'MANAGER', 'OPERATOR') AND
EMPLOYEE.HIREDATE BETWEEN '01/01/1995' AND '12/31/2004' AND
EMPLOYEE.BIRTHDATE > '01/01/1960' AND
EMPLOYEE.BIRTHDATE <= '12/31/2002' AND
EMPLOYEE.EMPNO LIKE '000%' AND
EMPLOYEE.EDLEVEL >= 14 AND
EMPLOYEE.SALARY BETWEEN 45000 AND 58000 AND
EMPLOYEE.BONUS <= DECIMAL(600) AND
EMPLOYEE.COMM <= DECIMAL(2350.0) AND
EMPLOYEE.COMM >= DECIMAL(1400.0) AND
EMPLOYEE.SEX = 'M'
ORDER BY
EMPLOYEE.FIRSTNME,
EMPLOYEE.LASTNAME;
Let’s take a look at the “Access Plan” section in the generated db2caem.exfmt.1 file to see how it has changed:
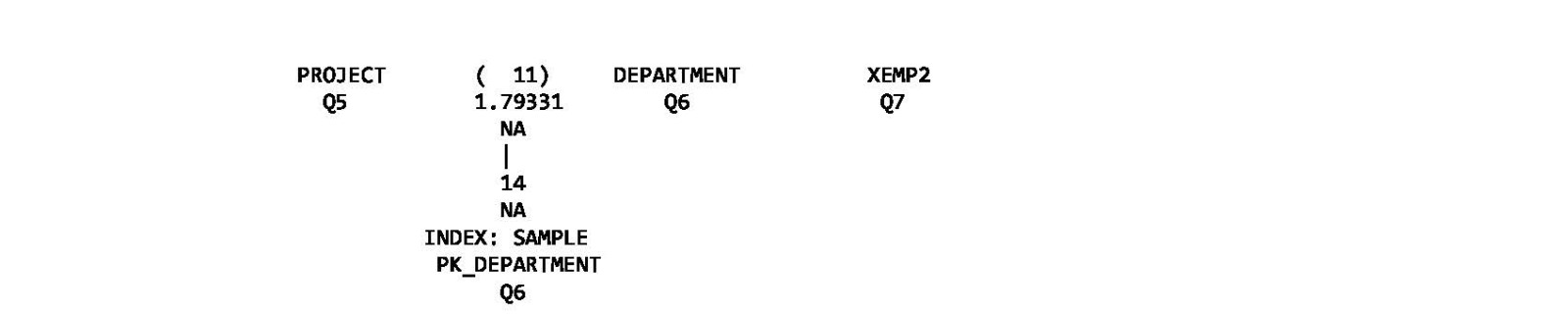
Access Plan:
-----------

 At first glance, this access plan might seem more expensive since the estimated cost is higher - 71.6 compared to our earlier access plan which had a cost of 61.5. However, a major factor in the estimated cost is how many rows are expected to flow through each operator, and so an access plan with significant cardinality under-estimations may have a lower estimated cost. A different access plan with a higher estimated total cost can still be a better access plan if it shows improved cardinality estimates, since the access plan estimates are more likely to match reality when the query is executed. Let’s dig deeper.
At first glance, this access plan might seem more expensive since the estimated cost is higher - 71.6 compared to our earlier access plan which had a cost of 61.5. However, a major factor in the estimated cost is how many rows are expected to flow through each operator, and so an access plan with significant cardinality under-estimations may have a lower estimated cost. A different access plan with a higher estimated total cost can still be a better access plan if it shows improved cardinality estimates, since the access plan estimates are more likely to match reality when the query is executed. Let’s dig deeper.
We can see the cardinality estimates for both the EMPLOYEE and PROJECT tables have changed. For the EMPLOYEE table, the cardinality estimate is 2.07 rows after applying local predicates (the actual number of rows is 5) and we no longer push down the join predicates since a hash join is used. For the PROJECT table, the cardinality estimate has improved to 3.69 rows after applying local predicates (the original estimate without AI Optimizer was 0.6 rows and actual cardinality is 4 rows).
We can also see these cardinalities contributed to an access plan change in the form of an alternate join order since both the EMPLOYEE and PROJECT tables are joined together. The final cardinality has also improved significantly to 14.63 rows (original was 0.51 rows) and is now roughly within one order of magnitude of the actual cardinality (319 rows).
This new access plan looks much better than the original access plan without the AI Optimizer. In this new access plan, the first join is between EMPLOYEE and PROJECT which applies more local predicates earlier, hash joins are used over nested loop joins with the final hash join having the smaller input stream on the inner, and the final cardinality estimate looks much more reasonable. To achieve this, all we did was allow the query optimizer to use models that were created automatically for us!
But how do we know that the AI Optimizer had something to do with these cardinality estimation changes on the EMPLOYEE and PROJECT tables? Access plans will include additional operator and object details about any AI Optimizer models that assisted with cardinality estimation. We will dive into these new access plan details below.
NOTE
These access plan details are not shown within section actuals access plans until Db2 12.1 mod pack 1, but they are shown inside access plans for explained queries. For example, you can explain query 1 using the EXPLAIN statement, and then format the access plan with the db2exfmt tool:
db2exfmt -d SAMPLE -1 -o plan.exfmt
The plan.exfmt file will contain the new model operator and object information we will discuss below.
For the EMPLOYEE table, let’s look at the details of the FETCH and IXSCAN operators (ellipses are used to skip over parts of the operator details):
13) FETCH : (Fetch)
Cumulative Total Cost: 14.2966
Cumulative CPU Cost: 187291
Cumulative I/O Cost: 1
Cumulative Re-Total Cost: 5.55321
Cumulative Re-CPU Cost: 138830
Cumulative Re-I/O Cost: 0
Cumulative First Row Cost: 11.5362
Estimated Bufferpool Buffers: 2
...
Table Cardinality Model Predicates:
-----------------------------------
Model: SYSIBM.SQL241021170053621900
Predicates:
23) (+000000000001400. <= Q7.COMM)
24) (Q7.COMM <= +000000000002350.)
25) (Q7.BONUS <= +00000000600.)
26) (Q7.SALARY <= 58000)
27) (45000 <= Q7.SALARY)
28) (14 <= Q7.EDLEVEL)
...
14) IXSCAN: (Index Scan)
Cumulative Total Cost: 3.5638
Cumulative CPU Cost: 89095
Cumulative I/O Cost: 0
Cumulative Re-Total Cost: 2.14536
Cumulative Re-CPU Cost: 53634
Cumulative Re-I/O Cost: 0
Cumulative First Row Cost: 1.95188
Estimated Bufferpool Buffers: 1
...
Table Cardinality Model Predicates:
-----------------------------------
Model: SYSIBM.SQL241021170053621900
Predicates:
7) (Q7.WORKDEPT <= 'D..')
8) ('D..' <= Q7.WORKDEPT)
There is a new section in each of these operators named “Table Cardinality Model Predicates”. This section contains the set of predicates on the EMPLOYEE table that were sent to the associated AI Optimizer cardinality estimation model to predict the combined cardinality of that set of predicates. When we see this new section appear in an operator’s details, it tells us that a model played some part in the final cardinality estimate for that operator.
We can see a “Table Cardinality Model Predicates” section in the TBSCAN of the PROJECT table as well:
12) TBSCAN: (Table Scan)
Cumulative Total Cost: 11.9162
Cumulative CPU Cost: 127781
Cumulative I/O Cost: 1
Cumulative Re-Total Cost: 3.08753
Cumulative Re-CPU Cost: 77188.1
Cumulative Re-I/O Cost: 0
Cumulative First Row Cost: 9.62815
Estimated Bufferpool Buffers: 1
...
Table Cardinality Model Predicates:
-----------------------------------
Model: SYSIBM.SQL241021170112163725
Predicates:
33) ('000019' < Q5.RESPEMP)
34) (Q5.PRSTAFF < 13)
35) (Q5.PRENDATE <= '12/31/2003')
36) ('12/31/2001' <= Q5.PRENDATE)
This means the associated model on the PROJECT table also played a part on the cardinality estimate for TBSCAN 12.
Finally, the “Objects Used in Access Plan” section at the bottom of the access plan will also show model object information (model name and columns) for each table in the access plan that has a model trained on it. For example, we see the following model information for the EMPLOYEE and PROJECT tables:
Schema: SAMPLE
Name: EMPLOYEE
Type: Table
Time of creation: 2024-10-21-16.58.00.766060
Last statistics update: 2024-10-21-17.00.53.618679
Number of columns: 14
Number of rows: 42
...
Model Schema: SYSIBM
Model Name: SQL241021170053621900
Columns in model:
BONUS
COMM
EDLEVEL
EMPNO
FIRSTNME
JOB
LASTNAME
MIDINIT
PHONENO
SALARY
WORKDEPT
...
Schema: SAMPLE
Name: PROJECT
Type: Table
Time of creation: 2024-10-21-16.58.02.141120
Last statistics update: 2024-10-21-17.01.12.161821
Number of columns: 8
Number of rows: 20
...
Model Schema: SYSIBM
Model Name: SQL241021170112163725
Columns in model:
DEPTNO
MAJPROJ
PRENDATE
PROJNAME
PROJNO
PRSTAFF
PRSTDATE
RESPEMP
Controlling the AI Optimizer
Now that we’ve had a chance to take a look at the estimation power behind AI Optimizer models, let’s look at some options that can be used to control the behaviour of the AI Optimizer. We will look at ways to restrict model discovery and training as well as the usage of models inside the query optimizer.
Controlling Model Discovery and Training
Model discovery and training can be controlled in different granularities to allow for more flexibility and control of the models that get created: at the database level, the table level, and the model level.
Database Configuration Parameters
To disable all model discovery and training for the entire database, the AUTO_AI_OPTIMIZER database configuration parameter we discussed earlier can be switched to OFF:
UPDATE DATABASE CONFIGURATION FOR SAMPLE USING AUTO_AI_OPTIMIZER OFF;
No further models will be automatically discovered and trained, and no existing models will be considered for re-training. This is an effective option to use to completely switch off the AI Optimizer for the database, as disablement will also prevent the query optimizer from using any existing models for cardinality estimation. Note that any models that were created before disabling AI Optimizer will remain in the catalogs and will be available to be used once again if the AI Optimizer is re-enabled.
You can also disable all automatic AI database maintenance, including AI Optimizer (which as of Db2 12.1, is the only type of automatic AI database maintenance available), by switching AUTO_AI_MAINT to OFF:
UPDATE DATABASE CONFIGURATION FOR SAMPLE USING AUTO_AI_MAINT OFF;
Another option that will just disable model discovery but not prevent re-training of existing models (when automatic statistics collection detects the associated table has high levels of insert, update, or delete activity), is to switch off the AUTO_MODEL_DISCOVER database configuration parameter:
UPDATE DATABASE CONFIGURATION FOR SAMPLE USING AUTO_MODEL_DISCOVER OFF;
This is an effective option to use to lock down all the trained models that have been created up to this point to prevent newly discovered model columns from being added to them. Disabling model discovery is a good way to keep existing models’ performance stable and also prevent any further storage from being taken up for larger models.
Finally, switching AUTO_RUNSTATS to OFF will also prevent model discovery and training for the entire database even if AUTO_AI_OPTIMIZER remains enabled.
AI Optimizer Policies
Model discovery and training can also be controlled at the table level using AI Optimizer policies. AI Optimizer policies are used to configure which tables are allowed to have models discovered and trained on them. For example, if the EMPLOYEE table does not have a model defined on it and an AI Optimizer policy exists to exclude the EMPLOYEE table, the policy will prevent a model from being discovered and trained on it.
You can find an example template of an AI Optimizer policy in the samples directory of your Db2 installation. Here’s an example of such a policy that excludes the EMPLOYEE and PROJECT tables:
<?xml version="1.0" encoding="UTF-8"?>
<DB2AutoAIOptPolicy xmlns="http://www.ibm.com/
<ModelDiscoveryTableScope modelType='TableCardModel'>
<FilterCondition>WHERE (TABSCHEMA,TABNAME) NOT IN
(VALUES ('SAMPLE','EMPLOYEE'),('
</FilterCondition>
</DB2AutoAIOptPolicy>
This policy can be applied by invoking the SYSPROC.AUTOMAINT_SET_POLICY or SYSPROC.AUTOMAINT_SET_POLICYFILE routines with the AUTO_AIOPT policy type.
Note that for existing models, a new AI Optimizer policy will still prevent further discovery for that model, but not prevent it from being re-trained automatically if needed. Similar to database disablement, applying an AI Optimizer policy after existing models are in place will help lock them down, and also ensure they are kept up to date (through re-training) as the table data changes over time.
Altering Models
Model discovery and training can be controlled at the model level using the new ALTER MODEL DDL statement. We can use ALTER MODEL to disable the model which will prevent further model discovery and training. Disabling the model will conveniently prevent the usage of it during query optimization as well.
There are two ways to disable a model. One way is by providing the name of the model to disable, and the second way is to use the name of the associated table. For example, here are the two ways to disable the model for the EMPLOYEE table:
ALTER MODEL SYSIBM.SQL241021170053621900 DISABLE;
ALTER MODEL ON SAMPLE.EMPLOYEE DISABLE;
Of course, in order to use ALTER MODEL, the model must already exist, so disabling the model in this way is a measure that can be useful in situations where an existing model needs to stop being used for all queries that involve the associated table.
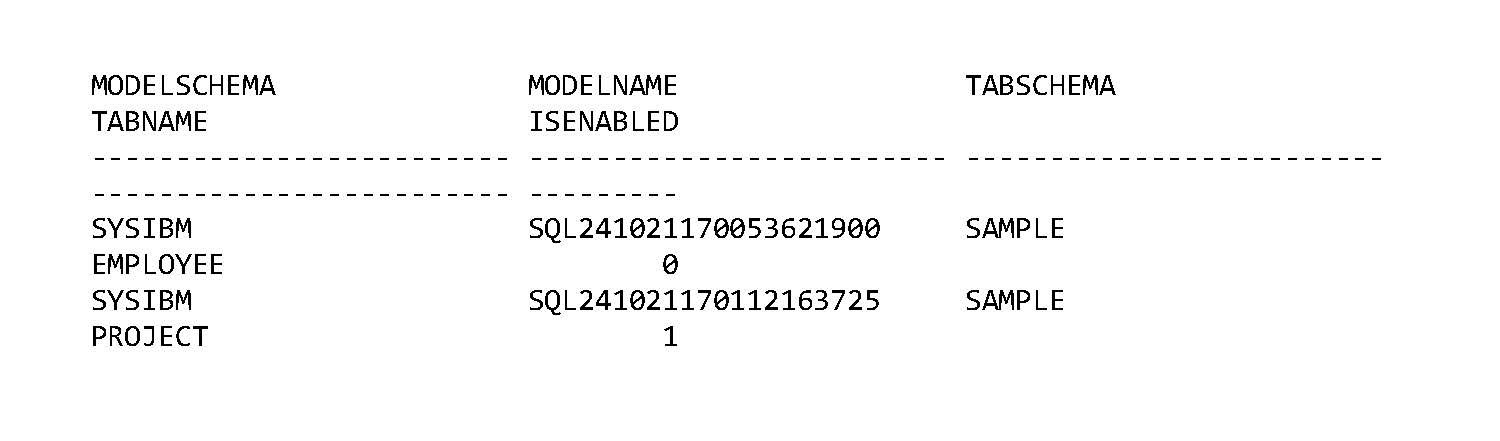
You can see which models are enabled and disabled by running the following query on the SYSCAT.AIOPT_TABLECARDMODELS catalog view:
SELECT
VARCHAR(MODELSCHEMA, 25) AS MODELSCHEMA,
VARCHAR(MODELNAME, 25) AS MODELNAME,
VARCHAR(TABSCHEMA, 25) AS TABSCHEMA,
VARCHAR(TABNAME, 25) AS TABNAME,
ISENABLED
FROM
SYSCAT.AIOPT_TABLECARDMODELS
WHERE
TABSCHEMA = 'SAMPLE' AND
TABNAME IN ('EMPLOYEE', 'PROJECT');
The ISENABLED column is 0 when the model is disabled and 1 when the model is enabled:
To re-enable the model, the same DDL statements can be executed above by replacing the DISABLE clause with ENABLE:
ALTER MODEL SYSIBM.SQL241021170053621900 ENABLE;
ALTER MODEL ON SAMPLE.EMPLOYEE ENABLE;
Controlling Model Usage
Model usage, or the use of the model within the query optimizer, can be controlled in different granularities: at the instance level, the database level, the model level, and the query level. We already covered the database and model levels: the AUTO_AI_OPTIMIZER database configuration parameter and ALTER MODEL DDL disablement will both prevent the model from being used.
We also saw an example earlier of controlling model usage at the query level using an optimizer guideline on query 1. The DB2_SELECTIVITY registry variable can apply a new registry setting, MODEL_PRED_SEL set to OFF instance wide using db2set:
db2set -immediate DB2_SELECTIVITY="MODEL_PRED_SEL OFF"
or on a per-query basis using an optimizer guideline:
/*<OPTGUIDELINES>
<REGISTRY>
<OPTION NAME='DB2_SELECTIVITY' VALUE='MODEL_PRED_SEL OFF'/>
</REGISTRY>
</OPTGUIDELINES>*/
The same guideline can also be applied within an optimizer profile to prevent model usage on multiple queries sharing a similar structure.
When a model is controlled using one of these methods so that it is not to be used for query optimization, the traditional optimizer cardinality estimation algorithms are used. This is equivalent to no model being available for the associated table.
AI Optimizer model objects take up on average a few tens of kilobytes in storage. If it is necessary to remove some model objects, the DROP DDL statement has been extended to allow for model objects to be dropped.
TIP
If you are curious to see how much storage each model takes, sorted by size in kilobytes, the following query can be executed (SYSIBM.SYSAIMODELS is the catalog table that contains the MODEL column where each model is stored):
SELECT
VARCHAR(MODELSCHEMA, 25) AS MODELSCHEMA,
VARCHAR(MODELNAME, 25) AS MODELNAME,
VARCHAR(TABSCHEMA, 25) AS TABSCHEMA,
VARCHAR(TABNAME, 25) AS TABNAME,
LENGTH(MODEL) / 1024 as MODELSIZE_KB
FROM
SYSCAT.AIOPT_TABLECARDMODELS TCM,
SYSIBM.SYSAIMODELS SAI
WHERE
TCM.MODELSCHEMA = SAI.SCHEMA AND
TCM.MODELNAME = SAI.NAME
ORDER BY MODELSIZE_KB DESC;
Similar to the ALTER MODEL command, DROP MODEL can be used with the model name or the associated table name:
DROP MODEL SYSIBM.SQL241021170053621900;
DROP MODEL ON SAMPLE.EMPLOYEE;
Keep in mind that it is possible for dropped models to get recreated automatically by the automatic statistics collection facility. To prevent the recreation of the models, exclude the associated tables using an AI Optimizer policy before dropping the models.
Conclusion
We went though a lot of content about the AI Optimizer and we’ve just scratched the surface! Hopefully by following along, you learned a little bit about how to use, evaluate, and control the AI Optimizer and are encouraged to try it out for your own use cases. The AI Optimizer is a powerful new feature in Db2 12.1, and I am excited to see how it will help you automatically improve your query performance.
References
- Zuzarte, Calisto. The AI Query Optimizer in Db2. IDUG. 2024-05-24.
- Zuzarte, Calisto & Corvinelli, Vincent. The AI Query Optimizer Features in Db2 Version 12.1. IDUG. 2024-08-12.
- Finnie, Liam. The Neural Networks Powering the Db2 AI Query Optimizer. IDUG. 2024-10-17.
Brandon Frendo is a software developer within IBM's Db2 Query Compiler and AI team. Since joining IBM in 2015, Brandon has contributed to a variety of query optimization improvements and is currently one of the infrastructure leads for the Db2 AI Query Optimizer.