The AI Query Optimizer Features in Db2 Version 12.1
By Calisto Zuzarte and Vincent Corvinelli
Introduction
The AI Optimizer in Db2 blog post introduced the motivation for the AI query optimizer in Db2. This blog focuses on the high-level features covered in the first release of the AI query optimizer.
For years, diamond polishing has been done by people who have spent years honing their skills to be able to judge how to cut diamonds to maximize its brilliance, weight retention and value. Diamond cutting has traditionally been done by craftsmen that have generations of experience. About 90% of the world’s diamond roughs are sent to be cut and polished in Surat, India and the rest sent to Guangzhou and Shenzhen in China (https://en.wikipedia.org/wiki/Diamond_cutting). Artificial Intelligence may turn this industry up-side down. Recent advances have shown that AI can analyze the structure of a diamond and suggest how to optimally cut diamonds for maximum market value much faster than humans can.
The Db2 query optimizer has been continuously maintained and improved over time as features, hardware and configurations have evolved. The deep skills and experience necessary to evolve the optimizer is not unlike the skills needed to cut diamonds. Evolving the Db2 optimizer based on artificial intelligence will usher the next generation optimizer technology. As laid out in the previous blog (The AI Optimizer in Db2), AI will be infused gradually. The initial functionality will focus on one of the most consequential functions in a cost-based optimizer, cardinality estimation, or the number of rows flowing in and out of low-level operators in the query execution plan.
Cardinality Estimation
The Db2 cost-based optimizer produces an optimal query execution plan that minimizes the cost estimate. The cardinality estimate is the single most important input to the optimizer cost functions, and its accuracy is dependent on accurate statistics. For example, after applying predicates in a scan operator, the number of rows might reduce from several million rows to a few rows. In this case it likely becomes more efficient to use an index scan as opposed to a table scan to optimize the access to that data. Inaccurate estimation of this cardinality can result in a poor choice in the query execution plan, leading to slow or unstable query performance.
Achieving accurate cardinality estimation uses statistics that have traditionally been difficult or expensive to collect. Multiple predicates on columns in a table that have statistically correlated data result in problematic (often underestimated) cardinality estimates. The default set of statistics collected during RUNSTATS are independent single column statistics that do not capture the data value correlation. Collecting statistics on column groups can minimize these estimation errors with multiple equality predicates. However, it is usually cumbersome to cover and store the statistics for all required combinations of column groups. Even if column group statistics are collected, the traditional Db2 optimizer does not handle statistical correlation when range predicates are involved. To account for statistical correlation when range predicates are involved, specific statistical views, likely covering different combinations of values referenced in the range predicates, must be created and maintained, adding to the burden of tuning for performance.
The AI query optimizer solution for cardinality estimation uses a single table cardinality estimation model that learns the distribution and underlying correlations of the data in the table across columns. Given a set of predicates, the model is used to predict the cardinality estimates more accurately by capturing correlations for a variety of predicate types including equality, range, between, IN, and OR predicates involving a column and a constant. Predicates with expressions or parameter markers are handled by the traditional optimizer algorithms.
A model is built for each table, learning the distribution of each column and the joint distribution of the combinations of columns. An artificial neural network is used to learn and approximate selectivity functions for basic BETWEEN predicates that cover one or more columns in the same table. All other predicates are expressed in this form during training and inference. For example, equality predicates are represented as range predicates where the lower bound and the higher bound are the same. A single range predicate uses the upper bound or lower bound of the column domain of values to compose the BETWEEN predicate. Other predicate types such as IN and OR predicates also have their estimates derived from the basic BETWEEN predicate form.
Integration of the model in the optimizer is accomplished in a seamless way such that anything that is not covered by the table cardinality model uses the traditional optimizer. The AI models are used in conjunction with the traditional optimizer, allowing the system to handle queries of the same complexity that are currently handled. For example, while predicates with parameter markers of the form c1 >=? are not handled by the model, they are handled using the traditional optimizer algorithms while other supported predicates in the same query are handled using the model. The combined selectivity of the supported and unsupported predicates is computed as the product of the traditional and model estimates, which results in an independence assumption between the supported and unsupported predicates.
Architecture and Automation
The AI query optimizer capability in Db2 is architected in a way that is open to future enhancements, where targeted traditional optimizer features can be replaced or augmented by learned models.
The initial scope of building the models uses the same automatic maintenance facility used to automatically collect statistics. The user will not be able to initiate the training and maintenance of the models, however a policy can be defined to indicate which tables are to be included or excluded from consideration when building models. The cardinality estimation for predicates on tables that are excluded will default to using the estimation provided by the traditional optimizer.
The core architecture of the AI query optimizer is built around a complete automatic approach relying on the following components:
- Automatic training infrastructure to discover models and train them using automatically generated queries
- Predicate selectivity estimation using model
- Automatic feedback for model retraining
Automatic Training Infrastructure
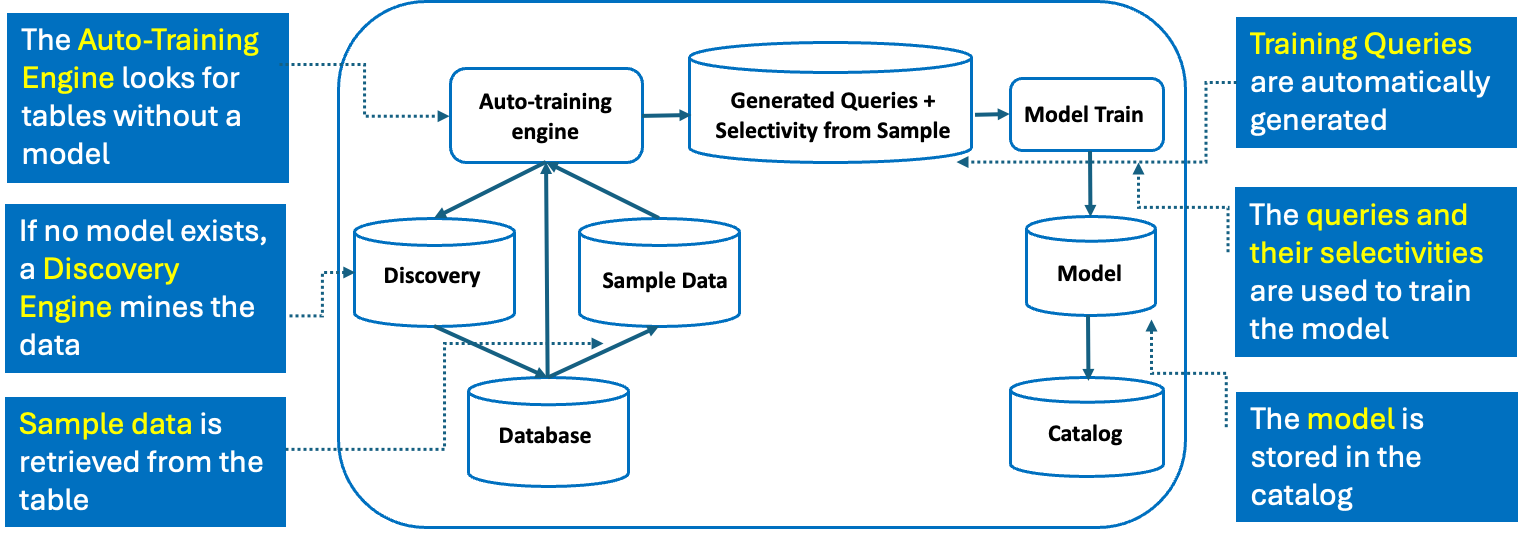
Figure 1: Framework for automated model training.
Figure 1 illustrates the framework for automated discovery and training of the single table cardinality estimation models, using the same engine that drives the automatic collection of statistics on the tables in the database.
The discovery module mines the data using a sample to find strongly correlated columns that identifies and ranks columns that will benefit the most from the model. This functionality helps keep the training time low by focusing on strongly correlated columns. Cardinality estimation for predicates on columns that are not included in the model will be handled independently using the traditional statistics available.
Model training is performed using the same sample used to collect statistics, automatically generating training and validation query sets. The generated queries include various combinations of BETWEEN predicates on the columns captured by the model and are run against the sample to compute the selectivity estimate used as the label for training. The predicate pattern and the selectivity estimate for each query is encoded and used to train and build the model. The trained models are stored in system catalogs.
Predicate Selectivity Estimation Using the Model
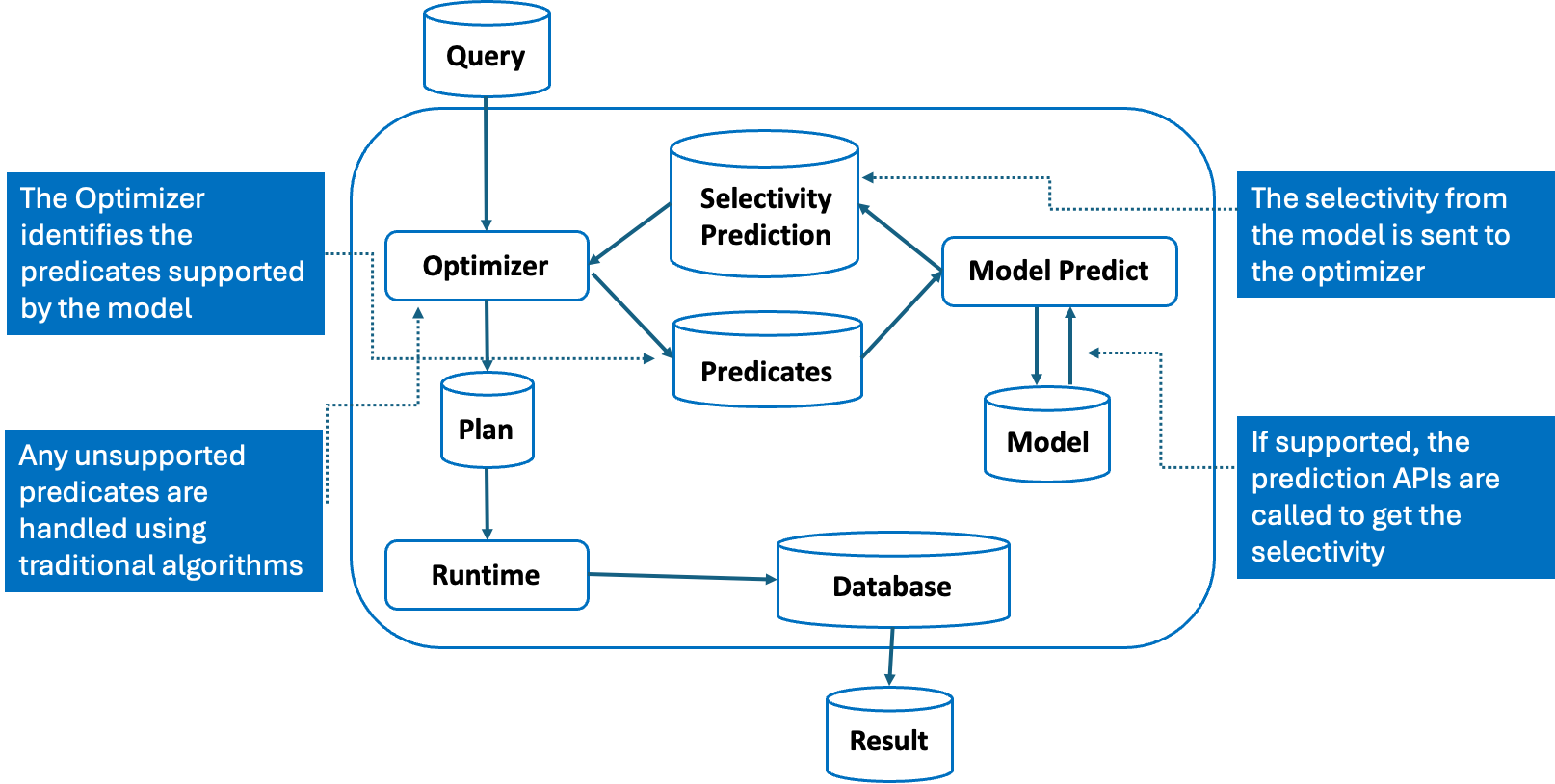
Figure 2: Framework for query predicate selectivity estimation using a learned model.
If a model exists, the optimizer calls the model prediction interface, supplying a combination of all supported predicates expressed in terms of BETWEEN predicates for each applicable column encoded by the model equivalent to how the training queries were encoded. This process is depicted in Figure 2. The selectivity returned provides the combined predicate selectivity. Once returned to the optimizer, any unsupported predicates using the learned model will be computed using the traditional optimizer algorithms.
Automatic feedback for model retraining
The retraining of models is determined using the same table data change analysis performed by automatic statistic collection where statistics from a sample of the new data are compared to that previously collected to compute a data change measure. This approach used is like the task of detecting data drift in typical AI models. Retraining of the model is performed in the same manner as the initial model training using generated queries based on a sample of the current data in the table.
Experimental Results
The design goals for the Db2 AI query optimizer include achieving reasonable accuracy and robustness while minimizing model size and training time.
A workload based on real-world scenarios was developed to compare the traditional Db2 optimizer to the AI query optimizer. This workload included some real-world scenarios of problematic queries consisting of join queries with multiple local predicates applied on the tables joined, and consisting of a mix of equality, range/between, IN and OR predicates. These queries highlight the limitation of the traditional Db2 optimizer where it does not account for statistical correlation between multiple range predicates on different columns or between range predicates and equality predicates.
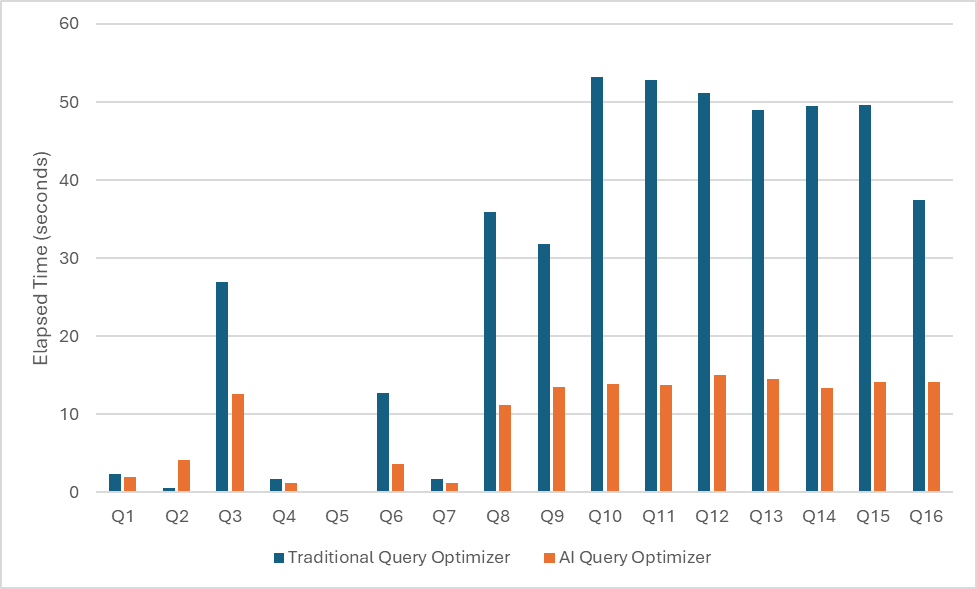
Figure 3: Comparing Traditional Query Optimizer to AI Query Optimizer.
Figure 3 compares the elapsed time of each query using the traditional query optimizer cardinality estimates and the AI query optimizer cardinality estimates. Overall, the workload improved by 3X using the AI query optimizer estimates. In practice, the average benefit will depend on how much of an impact the cardinality estimates using the traditional optimizer algorithms has on the final query execution plan chosen. For example, improved cardinality estimates from the AI query optimizer for a particular query may suggest that an index scan is still more optimal than a table scan. A database that has been highly tuned with advanced statistics such as column groups and statistical views will unlikely see as significant of a benefit.
To better understand how the cardinality estimate influences the optimizer’s decision making, let’s compare the query execution plans for one of the queries, Q8, where the query execution performance improved by 3X using the table cardinality model. The SQL is as follows:
SELECT
IH.AMOUNT, CHD.COMMENTS
FROM
DEMO.PURCHASE_HISTORY PH,
DEMO.INSURANCE_HISTORY IH,
DEMO.CREDIT_HISTORY_DATA CHD,
DEMO.POLICE_DATA PD,
DEMO.SENTIMENT_SCORE_DATA SSD
WHERE
PH.INSURANCE_ID = IH.INSURANCE_ID AND
PH.PURCHASE_DATE BETWEEN '2014-01-01' AND '2019-12-31' AND
PD.EMAILID = PH.EMAILID AND
PD.CRIMINAL_RANK > .4 AND
PD.EMAILID = SSD.EMAILID AND
SSD.SCORE < .7 AND
PH.EMAILID = CHD.EMAILID AND
CHD.PAY_0 IN (0,1,2) AND
CHD.PAY_2 BETWEEN 0 AND 2 AND
CHD.PAY_3 BETWEEN 0 AND 2 AND
CHD.PAY_5 BETWEEN 0 AND 2 AND
CHD.PAY_6 BETWEEN 0 AND 2 AND
CHD.PAY_4 BETWEEN 0 AND 2 AND
CHD.BILL_AMT1 BETWEEN 150 AND 746814 AND
CHD.BILL_AMT2 BETWEEN 0 AND 743970 AND
CHD.BILL_AMT3 BETWEEN 0 AND 689643 AND
CHD.BILL_AMT4 BETWEEN 0 AND 706864
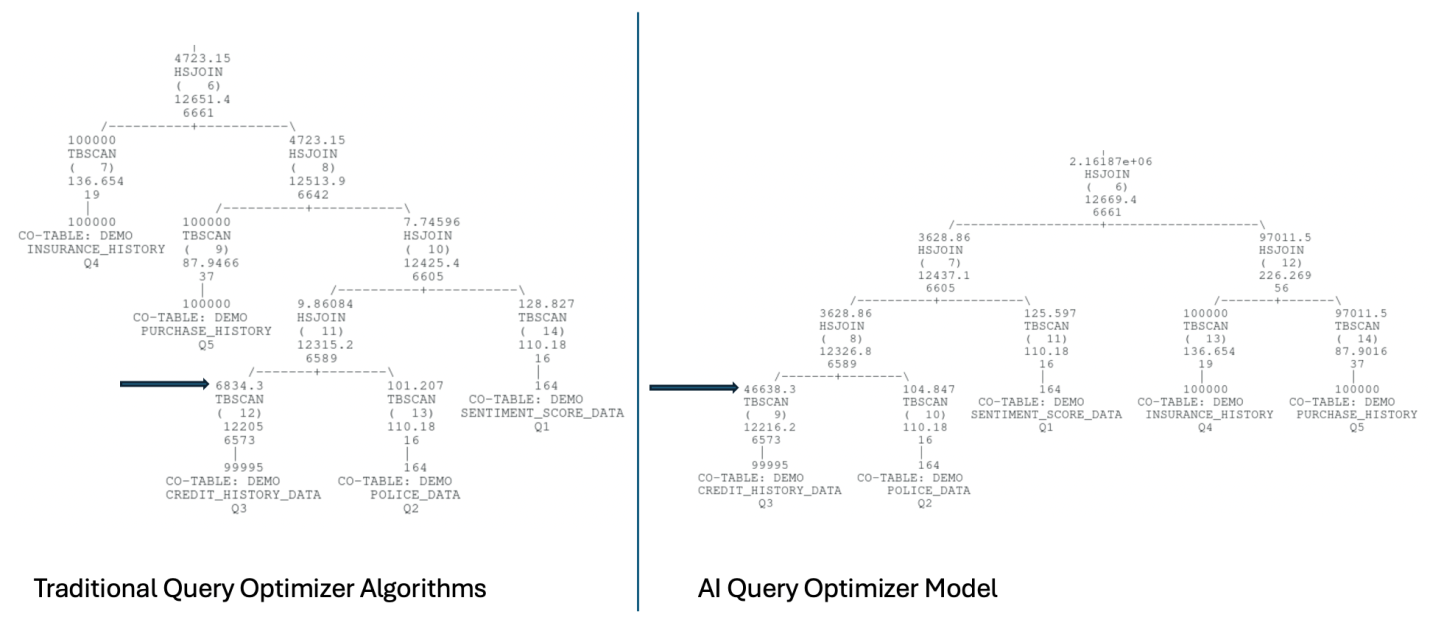
Figure 4: Comparing Query Execution Plan Chosen
Using Traditional and AI Query Optimizer
In Figure 4, the query execution plan on the left side is computed using the traditional query optimizer algorithm and the plan on the right is computed using the AI query optimizer table cardinality model.
50000 rows are qualified by the predicates on the CREDIT_HISTORY_DATA, but with multiple between predicates applied together with an IN predicate, the traditional query optimizer algorithm to estimate the cardinality under-estimates the cardinality leading to a non-optimal query execution plan being chosen. The table cardinality model produces a significantly improved cardinality estimate very close to the actual. Improving the cardinality estimate provides the optimizer sufficient accuracy to avoid the sub-optimal join order chosen when the cardinality is under-estimated. This is a good example of where the table cardinality model shines as it captures the column correlation during training of the model on the user data.
To evaluate the accuracy of the model predictions, we generated over 32000 non-empty result queries consisting of 1-5 predicates applied on individual tables in the TPC-DS schema, from which we computed the Q-error. Q-error is used as an evaluation metric, which is the multiplicative factor of how the cardinality estimate differs from the true cardinality of a query. Q-error is computed as estimate/actual. Figure 5 plots the log(Q-error), comparing the model estimates (box plot on left) to the traditional optimizer algorithms, with automatic column group statistics collected (middle), as well as without (right). The box plots show the median as a line within the box, the first quartile above the box, and the third quartile below the box. By plotting the log(Q-error), we can identify both the magnitude of the errors as well as the direction; a value of 0 indicates a perfect estimate, a value > 0 indicates an over-estimation and a value < 0 indicates an under-estimation. Each unit on the plot represents an order-of-magnitude in error.
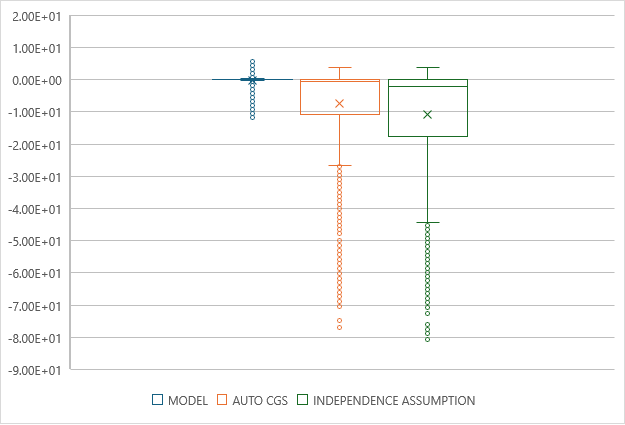
Figure 5: Comparing cardinality estimation using the model to traditional optimizer algorithms
We can see from the box plots that computing the cardinality estimates using the model significantly out-performs the traditional optimizer algorithms, with most of the estimates falling within an order of magnitude of the actual, with a slight tendency to overestimate, whereas the traditional optimizer algorithms show a wide range of errors, significantly under-estimating the cardinality.
Model Size and Training Time
To implement the model, several algorithms were evaluated including gradient boosted decision trees and artificial neural networks. All alternatives produced reasonable accuracy in the estimates. We settled on artificial neural networks since they resulted in models within 200 KiB in size (compared to decision tree models ranging in several MiB per model), and on average allowed training time under 1 minute, as shown in Table 1.
|
TABLENAME |
MODEL SIZE (KiB) |
TRAINING TIME (S) |
|
CALL_CENTER |
4.59 |
0.048 |
|
WAREHOUSE |
4.66 |
0.014 |
|
INCOME_BAND |
9.70 |
11.419 |
|
REASON |
10.58 |
24.479 |
|
HOUSEHOLD_DEMOGRAPHICS |
11.38 |
29.447 |
|
WEB_PAGE |
11.46 |
25.833 |
|
INVENTORY |
11.47 |
21.813 |
|
STORE |
11.48 |
13.76 |
|
SHIP_MODE |
11.51 |
20.183 |
|
PROMOTION |
19.20 |
30.53 |
|
CUSTOMER_DEMOGRAPHICS |
20.05 |
44.243 |
|
TIME_DIM |
34.89 |
46.42 |
|
WEB_SITE |
39.66 |
54.162 |
|
CUSTOMER_ADDRESS |
48.88 |
42.962 |
|
STORE_RETURNS |
54.47 |
62.888 |
|
WEB_RETURNS |
61.89 |
59.098 |
|
CATALOG_RETURNS |
62.16 |
53.914 |
|
STORE_SALES |
64.00 |
66.154 |
|
CATALOG_SALES |
64.70 |
52.401 |
|
WEB_SALES |
64.70 |
55.468 |
|
CATALOG_PAGE |
65.54 |
31.7 |
|
DATE_DIM |
67.70 |
45.587 |
|
CUSTOMER |
78.08 |
53.064 |
|
ITEM |
176.30 |
71.552 |
|
AVERAGE |
42.04 |
38.214 |
Table 1: Model Size and Training Time on TPC-DS Tables
Conclusions
Evolving the Db2 query optimizer based on artificial intelligence will usher the next generation query optimizer technology. This is not unlike the diamond cutting industry where AI-guided laser technology will revolutionize the process. Our experimental results show how the cardinality estimates using the AI query optimizer models improve upon the traditional query optimizer algorithms, with significant reduction in the estimation errors, avoiding the classic problematic issues of under-estimating the cardinality. In cases where those estimation errors negatively impact the optimizer’s choice in query execution plan, AI-guided improvements can result in significant gains in query execution performance and performance stability.
Calisto Zuzarte has been in Db2 development since Db2 was born. He has mainly been driving innovation in the optimizer components including the query rewrite engine and the plan optimizer. In the last few years, He has been involved in the evolution of the optimizer to the next generation AI Query Optimizer. More recently he drives the optimization strategies in the Query Optimizer as-a-service enabling significant query performance improvements in Presto C++ in Lakehouse environments.
Vincent Corvinelli is a senior developer in the Db2 Query Compiler and AI team at IBM. Since joining IBM in 2000, Vincent has worked on various query optimization features and improvements in Db2. Most recently, Vincent has been leading the transformation of the Db2 Query Optimizer based on artificial intelligence. You can reach him at vcorvine@ca.ibm.com.