Db2 and CDC in HADR governed by TSA
With replication of data becoming ever more popular and needed, even in a bi-directional way, infoSphere Data Replication (IIDR aka CDC) can be found today in many customer shops. With it comes the need to have a failover mechanism in place in conjunction with the bought replication solution.
An ‘out of the box’ setup for a Db2 cluster would be defined as follows: a Primary Db2 database server put in an HADR setup. If you want to have fail-overs automated, TSA add on top of it to act as a guardian. In case the database needs to replicate / receive data to / from another databases, the replication software is installed and points to the Primary. As a consequence, when the Standby acts as a new Primary – due to whatever reason, e.g. failure, upgrade, network outage, etc. – data is no longer replicated.
- Some terms explained before take off
If you are new to the subject, you should know upfront a few terms before continuing. I will describe the most important terms in just a few words, but will add where possible a URL referring to a page containing the complete and official description.
- CDC – this is a tool designed to replicate data from one database to another, as far as I know it does that by replaying on the receiving database all what is found in the (active) LOG files. You might know this product also as “Change Data Capture” or “InfoSphere Data Replication” (abbreviated to IIDR). Here is an overview of CDC Replication.
- CDC instance – is a daemon (dmts process) continuously running and containing a configuration towards a remote database amongst a few other settings. A CDC instance is not the same as a Db2 instance.
- CDC subscription – a list of logically grouped tables sharing the same source and target CDC instance.
- dmts process – see [CDC instance]
- Pointbase database – the CDC instance keeps all its information safe in a Pointbase database. When subscriptions are defined, the information of them are stored in the CDC instance operating as Source.
- HADR – High Availability and Disaster Recovery. By setting HADR up for a Db2 database, the content – from the Primary database – gets copied to a second node or more, also known as Standby database(s). When the Primary database has an issue, a manual take-over can be done by a Standby.
- TSA (MP) – Tivoli System Automation for Multiplaforms. TSA has the capability to facilitate automated take-over for an HADR configured database.
- Starting point
The above-mentioned documentation describes a setup with a single Db2 instance containing multiple databases and whenever a fail-over is done, all databases switch from Primary to Standby. On fail-over the CDC instance will follow the databases and will guarantee the fact that replication will continue despite of the fact the databases are now running on the Standby.
Many customers understand that we should be able to fail-over each database separately. When such a fail-over occurred, only the related CDC instance should follow.
This is not an out of the box behavior and so homemade coding is required. The architectural design is a combination of several customers requiring something similar.
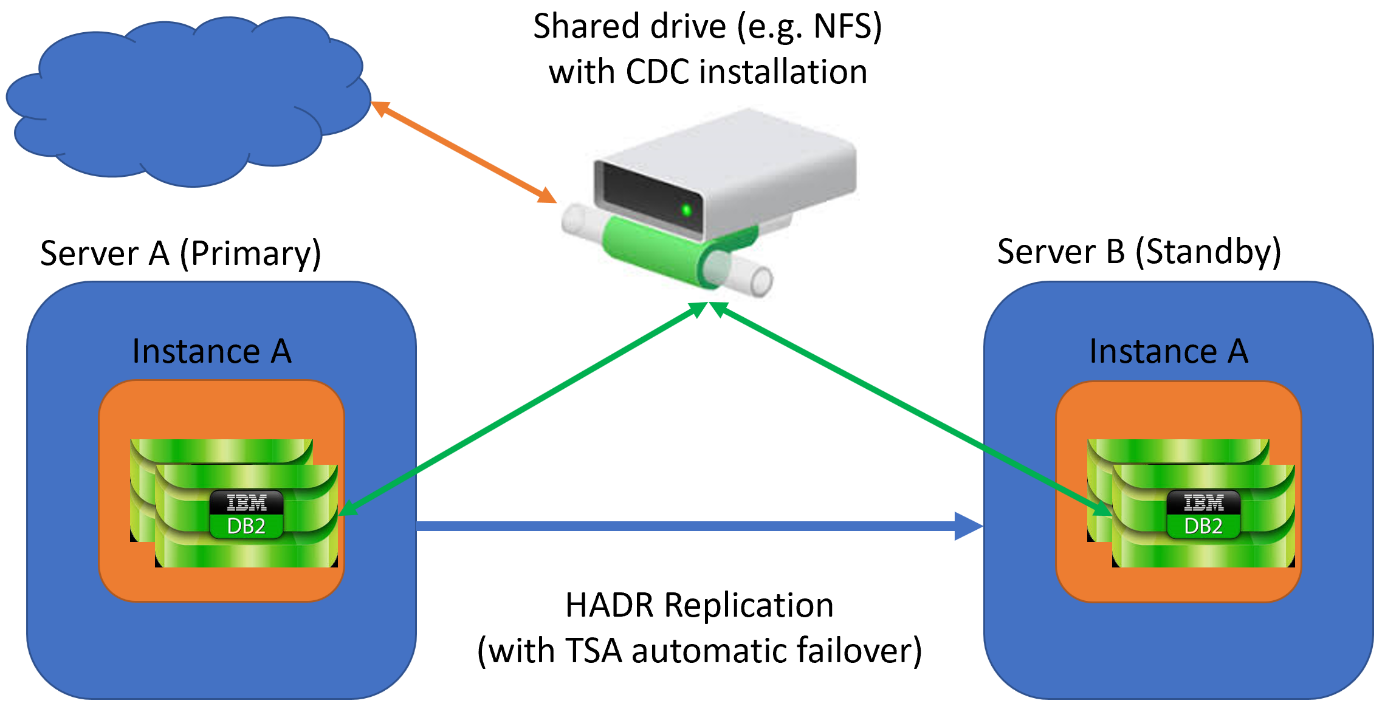
Figure 1 – The original setup
The setup as shown in Figure 1:
-
- A Db2 instance containing at least one database. This database sends and/or receives replicated data by means of CDC
- An HADR setup between a Primary and a Standby governed by a TSA doing automatic failover in case of need
- CDC installed on a shared drive, so both Primary and Standby can use the Pointbase database
- The final goal
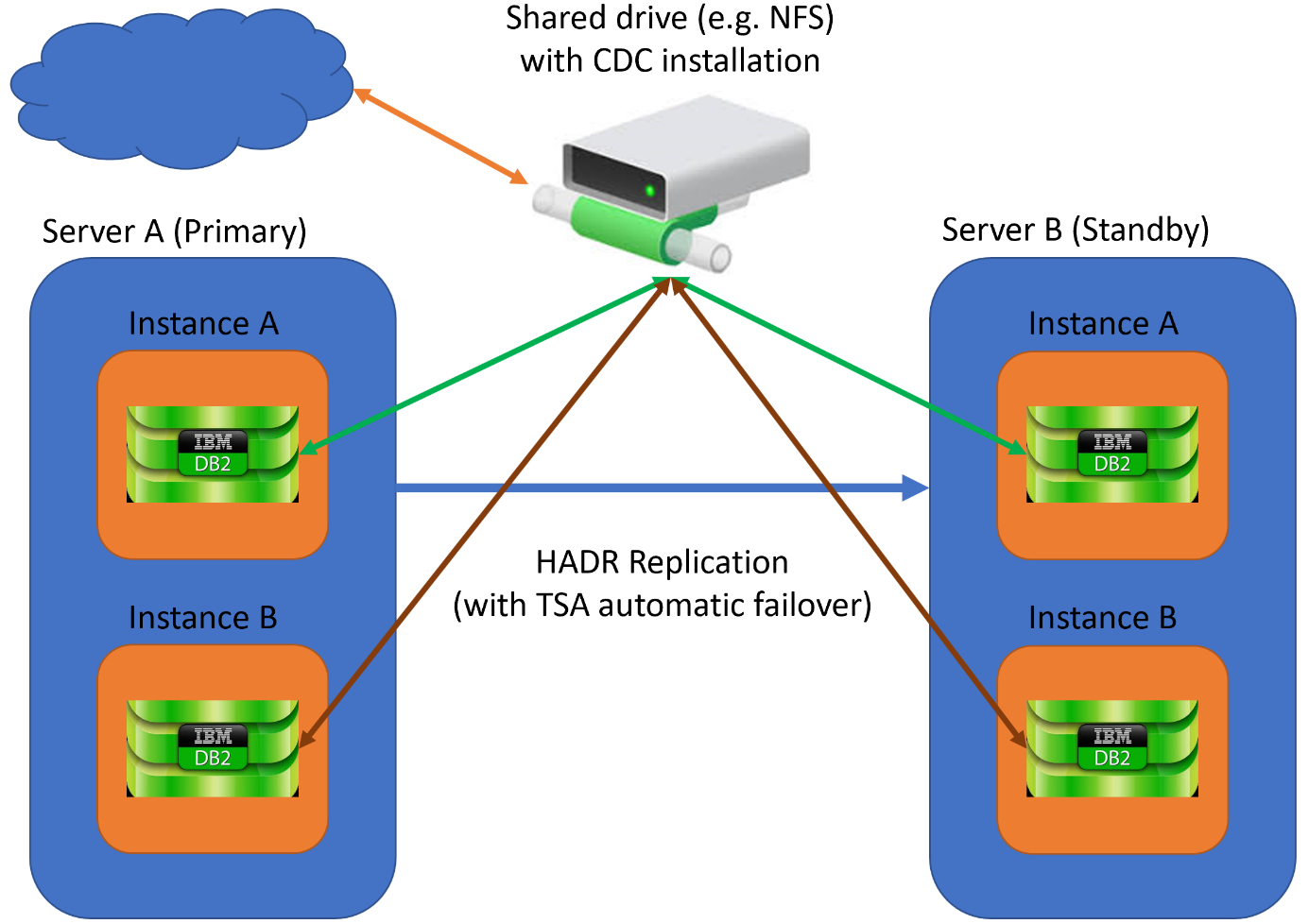
Figure 2
Figure 2 describes the following:
-
- Multiple instances just containing a single database sending / receiving data by means of CDC. The goal is to be able to fail-over a single database with its related CDC instance without interruption of any other database
- An HADR setup between a Primary and a Standby governed by TSA doing automatic failover in case of need for multiple instances separately
- CDC installed on a shared drive, so both Primary as Standby can use the same Pointbase database
- What is TSA expected to do?
In short what TSA does, boils down to the following:
-
- Start a resource set when it is down and should be online
- Stop a resource set when it has to be offline
- Monitor the status of the Resource Set and try to act on this status, e.g. fail-over between Primary and Standby
Each of the actions above can be handled by scripts, e.g. START.sh, STOP.sh and MONITOR.sh and when the Resource Set is created within TSA, each of the three actions gets assigned one of these scripts. The original scripts (see "Resource 1") held the parameters which identified the hard-coded CDC Resource Set. That wouldn’t work if we were to re-use the same script for databases within multiple instances.
- Emulating TSA before setting it up
A topic most customers struggle with the most, is understanding what TSA performs under the covers as it seemed that TSA makes decisions on its own and you have little control on it. You’ll find some useful ideas in the scripts in /use/sbin/rsct/sapolicies/db2 and e.g. start adding more logging into the START/MONITOR/STOP scripts.
Note: TSA is set up as a root process but it runs every script as a particular user (su -). Testing the scripts can thus be done by logging on as this user and executing the scripts manually. By checking whether processes are started / stopped, what the return code of the script is, and looking at the content of your logging scripts, you get a good idea what is happening and what should be the result within TSA as it executes the scripts on its own. TSA does no decent logging on its own!
Hint 1: you want to test the changes within the original CDC-scripts without setting up a cluster and installing the CDC software on a shared drive. To emulate a continuously running daemon process, chose to replace the dmts process by a Unix script doing basically nothing but sleeping. Adapt the TSA scripts as such so they would use this dmts.sh script instead of the dmts binary.
Hint 2: keep the logging within the START/MONITOR/STOP scripts to a strict minimum … which is still a big deal more than what TSA produces. Do log which Resource Set is doing what on which server. This is particularly a good idea to incorporate within the monitor script.
Some snippets of logging corporated within the START script:
scriptID="${HOSTNAME} : {${CDCUSER},${CDCDATABASE}} : ${script}"
DATE=$( date '+%Y-%m-%d %H:%M:%S' )
echo "${DATE} ${scriptID} : Start script is started" ]] ${LOGNAME}
…
DATE=$( date '+%Y-%m-%d %H:%M:%S' )
echo "${DATE} ${scriptID} : Start script Clear CDC staging store" ]] ${LOGNAME}
…
DATE=$( date '+%Y-%m-%d %H:%M:%S' )
echo "${DATE} ${scriptID} : Start script start subscriptions" ]] ${LOGNAME}
Examples of used scripts / script calls:
* cat dmts.sh
#!/bin/sh
#
# Do a whole lot of nothing but wasting CPU and sleeping
#
while [ true ]
do
maximumNumber=1000
currentNumber=0
while [ ${currentNumber} -le ${maximumNumber} ]
do
sleep ${maximumNumber}
currentNumber=$(( currentNumber + 1 ))
done
done
* /work/CDCTSA/CDCstart.sh "[CDC admin user]" "[database]" "[CDC instance]"
-
- should start CDC instance related dmts process
(verify with ps -ef | grep dmts | grep "[CDC admin user]")
- should start CDC instance related dmts process
-
- should return with a status 0 (OK!)
* /work/CDCTSA/CDCmonitor.sh "[CDC admin user]" "[database]" " CDC instance]"
- should return with a status 0 (OK!)
-
- should return with a status 1 (OK!)
- when it returns with a status 2, something went wrong
* /work/CDCTSA/CDCstop.sh "[CDC admin user]" " [database]" " CDC instance]"
-
- should stop the CDC instance related dmts process
(verify with ps -ef | grep dmts | grep "[CDC admin user]")
- should stop the CDC instance related dmts process
-
- should return with a status 0 (OK!)
- The preparation continues: create a CDC Resource Set with CDCsetup.sh
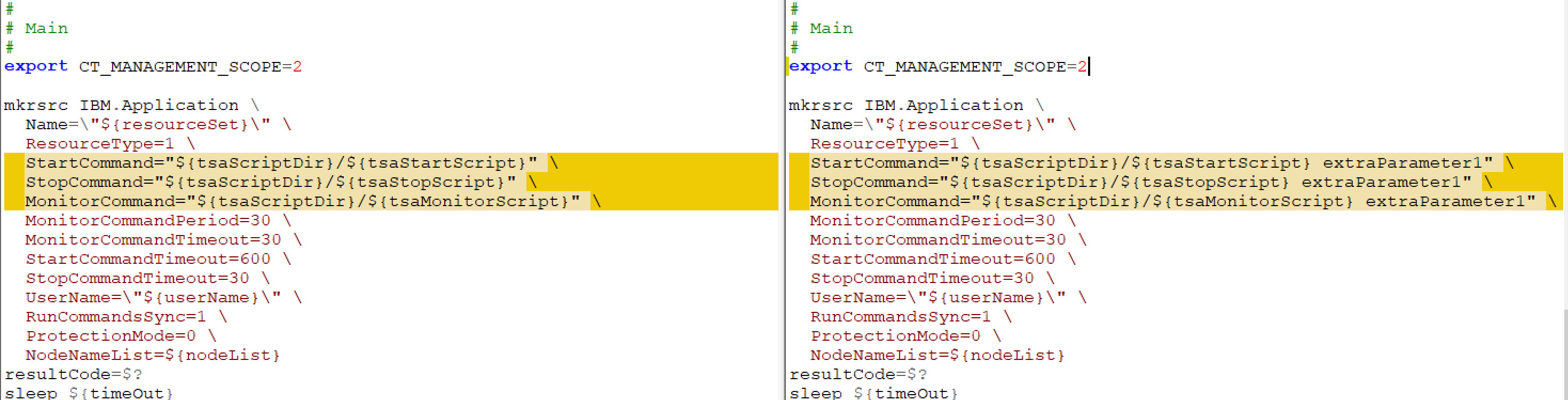
Figure 3 – CDCsetup.sh: Example of adding a Resource Set with(out) parameters. The script on the left is the original one.
The possibility to add parameters when creating a Resource Set, opens up the opportunity to add e.g. instance name, database name, and CDC instance. The newly build scripts are made to capture in such a way they capture these parameters and are already thoroughly tested (previous paragraph).
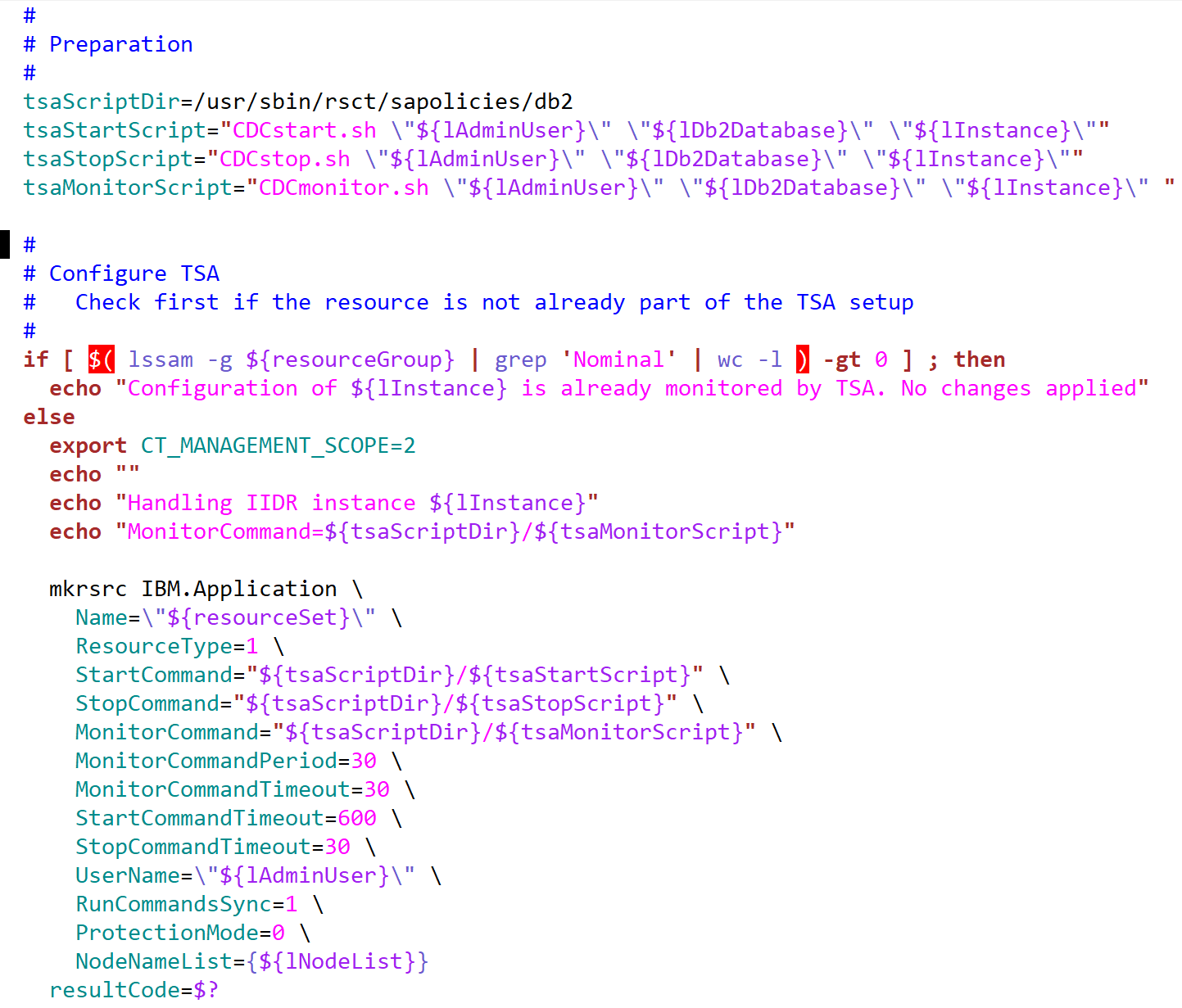
Figure 4 – Final CDCsetup.sh snippet: Adding a CDC Resource Set
The hardest parts are done once the scripts for START/MONITOR/STOP and SETUP (make TSA aware of what to monitor and what to do) are figured out. Looking at the original SETUP script, you’ll notice the link between the recently created CDC Resource Set and the related database is not yet established:
-
- Create a CDC Resource Group with an indicative name:
resourceGroup="CDC_[database instance]_[database name]_GROUP"
mkrg ${resourceGroup}
-
- Add the CDC Resource Set to the CDC Resource Group:
resourceGroup="CDC_[db instance]_[db name]_GROUP"
resourceSet="CDC_[db instance]_[db name]_DAEMON"
addrgmbr -g ${resourceGroup} IBM.Application:${resourceSet}
-
- Make sure the just create CDC Resource Group is OFFLINE!
- Create the relation between the CDC Resource Set and the Database Resource Set:
resourceGroup="CDC_[db instance]_[db name]_GROUP"
resourceSet="CDC_[db instance]_[db name]_DAEMON"
dbResourceSet="db_[db instance]_[db instance]_rs"
dependencyName="${resourceSet}_DependsOn_${dbResourceSet}"
mkrel -p DependsOn -S IBM.Application:${resourceSet} -G \
IBM.Application:${dbResourceSet} ${dependencyName}
-
- Bring the Resource Group online:
resourceGroup="CDC_[db instance]_[db name]_GROUP"
chrg -o Online ${resourceGroup}
I repeated the filling of the variables per bullet point to maintain readability. You’ll probably keep one single set of value assignments to variables in your SETUP script. You should come up with your own convention on how to name the Resource Group as Sets; make sure those names help you to quickly identify the resources.
Do not lose sight of the CDCremove script – this script is the opposite of the CDCsetup.sh script and removes the Resource Group and Set from the TSA configuration. When removing a Resource Group for one single instance, you should not remove by default the CDC related stuff all at once of the other CDC definitions. Removing the CDC fail-over mechanism for one database does not imply you need to remove those of others as well.
- Putting the puzzle together: setting up TSA to handle multiple CDC replicated databases in different instances on a same server
Note: You’ve got the choice to continue using the placebo dmts daemon process in a clustered environment if you still do not feel confident enough to already start installing and setting up CDC, at least that is what I did. As soon I was able to separately fail-over my own developed dmts daemon, I repeated all my steps, but this time with the CDC daemons.
Once the SETUP/START/MONITOR/STOP/REMOVE scripts are mature enough to put them into action, make sure:
-
-
- Have your DB2 cluster set up as described in paragraph 2
- Replace the placebo dmts with the correct one
- Adjust the additional parameters if necessary
- Copy the START/MONITOR/STOP scripts to the /usr/rsct/sapolicies/db2 directory – on BOTH the Primary as the Standby – and align the rights on the files to those scripts already available in the directory
- If you keep the logging (= writing to disk, because to screen does not make sense) enabled, make sure your CDC instance user can write to it
- Create the TSA resource set by executing the adapted CDCsetup.sh script
-
Reminder: When TSA performs a fail-over for a Resource Set, it fails-over all related Resources. When an instance is due for fail-over, all databases within that instance (Resource Group) are taken into account as well as the associated CDC Resource Group. To enable the ability to fail-over a single CDC replicated database – via TSA! – use different instances.
- Bumps on the road?
-
- As you might imagine there were many, but one in particular I wish to share with you: our first scripts were kind of brutal when it came to stopping CDC resources, we “kill”ed them even when there are other possibilities to gracefully stop the subscriptions and engine. We changed this part into steps that each become less graceful the more time it takes to stop a CDC resource:First, we attempt all the different options of ending the replication (dmendreplication)
- Secondly, we perform a shutdown of the CDC instance and wait a bit to give the applications the time to gracefully stop (dmshutdown). dmshutdown has some levels of its own, and we try them one by one:
- -c: Stop normal
- -i: Stop immediate
- -a: Abort all
- Finally, if applications related to the CDC instance are still running, perform a kill of the concerned processes (kill)
Over time we also came to realize that big chunks of code are shared by the START/MONITOR/STOP scripts. Since TSA is capable of running the scripts with parameters, it could be beneficial to combine the three scripts into a single one. Using the “mkrsrc” command would then be changed into something like:
mkrsrc IBM.Application \
Name=\"${resourceSet}\" \
ResourceType=1 \
StartCommand="/usr/sbin/rsct/sapolicies/db2/CDC_TSA.sh \"START\" \"${lAdminUser}\" \"${lDb2Database}\" \"${lInstance}\"" \
StopCommand="/usr/sbin/rsct/sapolicies/db2/CDC_TSA.sh \"STOP\" \"${lAdminUser}\" \"${lDb2Database}\" \"${lInstance}\"" \
MonitorCommand="/usr/sbin/rsct/sapolicies/db2/CDC_TSA.sh \"CHECK\" \"${lAdminUser}\" \"${lDb2Database}\" \"${lInstance}\"" \
MonitorCommandPeriod=30 \
MonitorCommandTimeout=30 \
StartCommandTimeout=600 \
StopCommandTimeout=30 \
UserName=\"${lAdminUser}\" \
RunCommandsSync=1 \
ProtectionMode=0 \
NodeNameList={${lNodeList}}
We didn’t go through with this change as the set up was already running and the added value of the change was not big enough. If you are about to start from scratch, you still might take it into consideration.
Most of the testing was done on isolated clusters to test the idea to have one single cluster hosting multiple CDC replicated databases which can be failed-over completely separate from each other. The documentation found on Developer works and the IDUG site were fundamental tools when implementing this particular setup. With this extra information you’ll get a good idea on how to proceed should you want to set this up yourself … but it isn’t really spelled out. A lot of trying and testing will be needed as adding too much detail would not make this document readable.